TIL (2024-07-22 ~ 2024-07-26) 2024-07-22 (월) 오늘 한 일
AWS Glue + Redshift Spectrum 공부 및 사용 여부 재결정
Redshift Spectrum 지원에 따라 두 서비스를 이용해서 진행하는 것으로 결정 다방, 직방의 테이블이 중복으로 적재되지 않아 공간적인 이점이 있음 그러나 외부 테이블을 사용하므로 비교적 시간이 오래 걸림 서비스의 역할
Glue : S3에 적재된 다방, 직방 데이터를 Crawler로 가져옴Redshift Spectrum : Glue에서 크롤링한 테이블을 외부 테이블로 사용해 병합 테이블 생성
부동산 중개업자 데이터 수집
저번 주(7/19)에 selenium으로 다운로드까지 되도록 코드 작성 Lambda로 Selenium으로 사용하려고 시도했지만 실패 -> Chrome에서 자꾸 막힘 팀원 분의 조언을 얻어 Airflow의 DAG로 직접 데이터 수집 시도 예정
Airflow에 Selenium을 설치하여 DAG로 직접 데이터 수집 진행 예정
내일 할 일
★ 오프라인 진행 (강남 교육장) AWS Glue, Redshift Spectrum 사용해서 병합 테이블 생성 진행해 보기
Crawler 자동화는 Glue에서 되는 것으로 알고 있음 Redshift에서 외부 테이블 참조 및 병합 테이블 생성은 Airflow DAG로 작성해야 할 듯 (시간이 된다면, DAG 작성까지 진행해 보자)
2024-07-23 (화) 오늘 한 일
직방 데이터를 사용한 AWS Glue + Redshift Spectrum 테스트 진행
선행 사항
S3 버킷에 test 폴더를 생성하고 샘플 데이터 저장 (spectrum_test/zigbang/zigbang.csv) Redshift에 AWSGlueServiceRole 역할 추가
확인해야 할 사항
AWS Glue에서 parquet으로 재저장 후 진행 -> 크롤링 단에서 parquet으로 저장 후 진행해 볼 예정 현재 직방 데이터만 확인하였고, 이제 다방 데이터 확인 후 병합하는 쿼리까지 작성해야 함 가능하면 AWS Glue의 Crawler는 사용하지 않고 진행하는 것이 심플한 형태가 될 것 같음
AWS Glue와 Redshift Spectrum 적용 과정 (직방 데이터) CREATE EXTERNAL SCHEMA external_schema
from data catalog
database 'spectrum_test'
iam_role 'Redshift에 적용한 AWSGlueServiceRole이 포함된 역할의 ARN'
create external database if not exists;
Redshift 외부 테이블 생성 (CSV)
생성이 완료되면, AWS Glue Data Catalog의 Table에 추가된 것을 확인 가능
Begin;
DROP TABLE IF EXISTS external_schema.zigbang;
CREATE EXTERNAL TABLE external_schema.zigbang(
room_id varchar(100),
room_type varchar(50),
service_type varchar(50),
area real,
floor varchar(50),
deposit integer,
rent integer,
maintenance_fee real,
latitude real,
longitude real,
address varchar(255),
property_link varchar(255),
registration_number varchar(100),
agency_name varchar(100),
agent_name varchar(100),
market_count smallint,
nearest_market_distance smallint,
store_count smallint,
nearest_store_distance smallint,
subway_count smallint,
nearest_subway_distance smallint,
restaurant_count smallint,
nearest_restaurant_distance smallint,
cafe_count smallint,
nearest_cafe_distance smallint,
hospital_count smallint,
nearest_hospital_distance smallint,
title varchar(4095),
description varchar(4095),
image_link varchar(255)
)
row format delimited
fields terminated by ','
stored as textfile
location 'csv 파일이 저장된 S3 경로(폴더 까지만)';
Commit;
AWS Glue에 생긴 테이블의 Schema 지정 및 parquet으로 재저장
csv 파일로 바로 쓰면, 파일 디코드가 잘못되는 것인지 이상하게 읽힘 parquet으로 변경하고 진행하니 올바르게 읽히는 것을 확인
AWS Glue Job
Redshift에 외부 테이블 생성 (parquet)
추가로 SELECT 속도가 csv 파일보다 빨라진 것을 확인 (5 sec → 1 sec)
-- platform 추가 필요
Begin;
DROP TABLE IF EXISTS external_schema.zigbang;
CREATE EXTERNAL TABLE external_schema.zigbang(
room_id varchar(100),
room_type varchar(50),
service_type varchar(50),
area real,
floor varchar(50),
deposit integer,
rent integer,
maintenance_fee real,
latitude real,
longitude real,
address varchar(255),
property_link varchar(255),
registration_number varchar(100),
agency_name varchar(100),
agent_name varchar(100),
market_count smallint,
nearest_market_distance smallint,
store_count smallint,
nearest_store_distance smallint,
subway_count smallint,
nearest_subway_distance smallint,
restaurant_count smallint,
nearest_restaurant_distance smallint,
cafe_count smallint,
nearest_cafe_distance smallint,
hospital_count smallint,
nearest_hospital_distance smallint,
title varchar(4095),
description varchar(4095),
image_link varchar(255)
)
stored as parquet
LOCATION 'parquet 파일이 저장된 S3 경로(폴더 까지만)';
Commit;내일 할 일
크롤링 단에서 parquet으로 저장된 데이터를 Redshift Spectrum을 사용해 받아오기 Airflow에서 Selenium을 사용해 중개업자 파일을 가져와 S3에 적재하도록 DAG 작성
2024-07-24 (수) 오늘 한 일
Airflow에서 Selenium 사용을 위한 시도
Dockerfile : Selenium 사용과 관련된 Chrome 설치requirements.txt : Selenium 추가docker-compose.yaml : 다운로드를 위한 data volume 추가다양한 요소를 추가로 설치하고 Docker를 Local로 수행하는 과정에서 디스크 용량 이슈 발생 어쩔 수 없이 진행했던 내용을 정리하여 다른 팀원 분에게 넘긴 상황
AWS Glue를 활용하여 ETL 작성 : 직방, 다방 데이터를 가져와 스키마 지정 후 병합 테이블 생성
이와 같이 Job을 작성하였지만, 막상 진행하고 생각해 보니 직방은 수집 형태가 달라서 적용이 힘듦 이에 따라 테이블 형태 회의 진행 (아래쪽에 결과가 있음)
AWS Glue Job
AWS Glue SQL Query : 중복 제거 및 병합 테이블을 생성
ROW_NUMBER() : 중복이 있다면, 첫 번째 것만 가져와서 중복 제거중복 체크를 위한 컬럼 : platform, address, floor, deposit, rent, maintenance_fee
WITH numbered_data AS (
SELECT room_id, platform, service_type, title, floor, area, deposit, rent,
maintenance_fee, address, latitude, longitude, registration_number,
agency_name, agent_name, subway_count, nearest_subway_distance,
store_count, nearest_store_distance, cafe_count, nearest_cafe_distance,
market_count, nearest_market_distance, restaurant_count,
nearest_restaurant_distance, hospital_count, nearest_hospital_distance,
property_link, image_link,
ROW_NUMBER() OVER (PARTITION BY platform, address, floor, deposit, rent, maintenance_fee ORDER BY room_id) AS rn
FROM (
SELECT room_id, platform, service_type, title, floor, area, deposit, rent,
maintenance_fee, address, latitude, longitude, registration_number,
agency_name, agent_name, subway_count, nearest_subway_distance,
store_count, nearest_store_distance, cafe_count, nearest_cafe_distance,
market_count, nearest_market_distance, restaurant_count,
nearest_restaurant_distance, hospital_count, nearest_hospital_distance,
property_link, image_link
FROM zigbang
UNION ALL
SELECT room_id, platform, service_type, title, floor, area, deposit, rent,
maintenance_fee, address, latitude, longitude, registration_number,
agency_name, agent_name, subway_count, nearest_subway_distance,
store_count, nearest_store_distance, cafe_count, nearest_cafe_distance,
market_count, nearest_market_distance, restaurant_count,
nearest_restaurant_distance, hospital_count, nearest_hospital_distance,
property_link, image_link
FROM dabang
) AS combined_data
)
SELECT room_id, platform, service_type, title, floor, area, deposit, rent,
maintenance_fee, address, latitude, longitude, registration_number,
agency_name, agent_name, subway_count, nearest_subway_distance,
store_count, nearest_store_distance, cafe_count, nearest_cafe_distance,
market_count, nearest_market_distance, restaurant_count,
nearest_restaurant_distance, hospital_count, nearest_hospital_distance,
property_link, image_link
FROM numbered_data
WHERE rn = 1;
테이블 형태 회의 결과
직방 : Airflow DAG를 활용해 Redshift에 직접 적재 (Diffrential)다방 : S3에 parquet 형태로 저장 후 외부테이블로 접근 (Full Refresh)병합 테이블 : 직방, 다방 테이블을 각각 가져와 병합 쿼리 수행
수행 과정 : 두 가지 방법 존재
Redshift에서 진행 : 고정 비용AWS Glue Job에서 진행 : 쿼리 수행에 따른 비용 발생Redshift는 고정 비용이므로 Redshift에서 처리하는 게 더 좋을 것 같음
내일 할 일
변경된 테이블 형태에 맞춰 병합 테이블 생성을 위한 Redshift 쿼리 작성
직방 : COPY로 샘플 데이터를 Redshift에 적재다방 : S3의 파일을 외부 테이블로서 가져옴
시간이 된다면, 작성한 쿼리를 자동화할 수 있도록 위의 쿼리를 Airflow DAG로 작성
2024-07-25 (목) 오늘 한 일
ERD의 데이터 형식 변경
pandas에서 값에 null이 있으면, object에서 int32 or int16으로 변환이 되지 않음 int32, int16으로 변환하되 후처리가 필요한 방식(참고 링크 저장 공간 측면에서 손해이지만, 존재하는 데이터 크기를 생각해 int64로 변환하는 걸로 결정
Github main Branch에 바로 Push 하는 실수 및 바로잡기
Git Bash에서 Branch 변환을 하지 않고 바로 Push를 해서 main에 적용이 됨 처음 겪은 일이라서 신속하게 찾아보고 원상 복구.. 휴,,(해결 과정 )
변경된 테이블 형태에 맞춰 병합 테이블 생성을 위한 Redshift 쿼리 작성
직방 데이터(.parquet) COPY : S3 -> Redshift
DROP TABLE IF EXISTS raw_data.zigbang;
CREATE TABLE raw_data.zigbang(
room_id varchar(100),
platform varchar(50),
room_type varchar(50),
service_type varchar(50),
area real,
floor varchar(50),
deposit bigint,
rent bigint,
maintenance_fee real,
latitude real,
longitude real,
address varchar(255),
property_link varchar(255),
registration_number varchar(100),
agency_name varchar(100),
agent_name varchar(100),
market_count bigint,
nearest_market_distance bigint,
store_count bigint,
nearest_store_distance bigint,
subway_count bigint,
nearest_subway_distance bigint,
restaurant_count bigint,
nearest_restaurant_distance bigint,
cafe_count bigint,
nearest_cafe_distance bigint,
hospital_count bigint,
nearest_hospital_distance bigint,
title varchar(4095),
description varchar(4095),
image_link varchar(255)
)
COPY raw_data.zigbang
FROM 's3://s3 파일 경로'
IAM_ROLE 'arn:aws:iam::S3 접근 권한을 가진 역할'
FORMAT AS PARQUET;
다방 데이터(.parquet) 외부 테이블로 가져오기 : S3 -> Redshift
%%sql
Begin;
DROP TABLE IF EXISTS external_schema.dabang;
CREATE EXTERNAL TABLE external_schema.dabang(
room_id varchar(100),
platform varchar(50),
service_type varchar(50),
title varchar(4095),
floor varchar(50),
area float,
deposit bigint,
rent bigint,
maintenance_fee real,
address varchar(255),
latitude float,
longitude float,
property_link varchar(255),
registration_number varchar(100),
agency_name varchar(100),
agent_name varchar(100),
subway_count bigint,
nearest_subway_distance bigint,
store_count bigint,
nearest_store_distance bigint,
cafe_count bigint,
nearest_cafe_distance bigint,
market_count bigint,
nearest_market_distance bigint,
restaurant_count bigint,
nearest_restaurant_distance bigint,
hospital_count bigint,
nearest_hospital_distance bigint,
image_link varchar(255)
)
stored as parquet
location 's3://s3 폴더 경로';
Commit;DROP TABLE IF EXISTS raw_data.property;
CREATE TABLE raw_data.property AS
WITH numbered_data AS (
SELECT room_id, platform, service_type, title, floor, area, deposit, rent,
maintenance_fee, address, latitude, longitude, registration_number,
agency_name, agent_name, subway_count, nearest_subway_distance,
store_count, nearest_store_distance, cafe_count, nearest_cafe_distance,
market_count, nearest_market_distance, restaurant_count,
nearest_restaurant_distance, hospital_count, nearest_hospital_distance,
property_link, image_link,
ROW_NUMBER() OVER (PARTITION BY platform, address, floor, deposit, rent, maintenance_fee ORDER BY room_id) AS rn
FROM (
SELECT room_id, platform, service_type, title, floor, area, deposit, rent,
maintenance_fee, address, latitude, longitude, registration_number,
agency_name, agent_name, subway_count, nearest_subway_distance,
store_count, nearest_store_distance, cafe_count, nearest_cafe_distance,
market_count, nearest_market_distance, restaurant_count,
nearest_restaurant_distance, hospital_count, nearest_hospital_distance,
property_link, image_link
FROM raw_data.zigbang
UNION ALL
SELECT room_id, platform, service_type, title, floor, area, deposit, rent,
maintenance_fee, address, latitude, longitude, registration_number,
agency_name, agent_name, subway_count, nearest_subway_distance,
store_count, nearest_store_distance, cafe_count, nearest_cafe_distance,
market_count, nearest_market_distance, restaurant_count,
nearest_restaurant_distance, hospital_count, nearest_hospital_distance,
property_link, image_link
FROM external_schema.dabang
) AS combined_data
)
SELECT room_id, platform, service_type, title, floor, area, deposit, rent,
maintenance_fee, address, latitude, longitude, registration_number,
agency_name, agent_name, subway_count, nearest_subway_distance,
store_count, nearest_store_distance, cafe_count, nearest_cafe_distance,
market_count, nearest_market_distance, restaurant_count,
nearest_restaurant_distance, hospital_count, nearest_hospital_distance,
property_link, image_link
FROM numbered_data
WHERE rn = 1;작성한 쿼리를 자동화할 수 있도록 Airflow DAG로 작성
직방 COPY를 제외한 쿼리들을 순차적으로 진행하는 DAG 작성
병합 테이블을 생성할 때, 트랜젝션 사용을 위해 DROP/CREATE가 아닌 DELETE/INSERT 사용
from airflow.providers.postgres.hooks.postgres import PostgresHook
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from airflow import DAG
from datetime import datetime
# Redshift 연결
def get_redshift_conn(autocommit=True):
hook = PostgresHook(postgres_conn_id = 'redshift_conn')
conn = hook.get_conn()
conn.autocommit = autocommit
return conn.cursor()
# S3의 다방 파일(.parquet)을 Redshift의 외부 테이블로 가져옴
def load_dabang_data(**context):
cur = get_redshift_conn()
schema = context["params"]["schema"]
table = context["params"]["table"]
url = context["params"]["url"]
try:
cur.execute(f"DROP TABLE IF EXISTS {schema}.{table};")
external_table_query = f"""CREATE EXTERNAL TABLE {schema}.{table}(
room_id varchar(100),
platform varchar(50),
service_type varchar(50),
title varchar(4095),
floor varchar(50),
area float,
deposit bigint,
rent bigint,
maintenance_fee real,
address varchar(255),
latitude float,
longitude float,
property_link varchar(255),
registration_number varchar(100),
agency_name varchar(100),
agent_name varchar(100),
subway_count bigint,
nearest_subway_distance bigint,
store_count bigint,
nearest_store_distance bigint,
cafe_count bigint,
nearest_cafe_distance bigint,
market_count bigint,
nearest_market_distance bigint,
restaurant_count bigint,
nearest_restaurant_distance bigint,
hospital_count bigint,
nearest_hospital_distance bigint,
image_link varchar(255)
)
stored as parquet
location '{url}';"""
cur.execute(external_table_query)
except Exception as error:
print(error)
raise
# 다방(외부 테이블)과 직방(적재된 상태)를 병합한 테이블을 Redshift에 적재
def load_merge_table(**context):
cur = get_redshift_conn()
schema = context["params"]["schema"]
table = context["params"]["table"]
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.{table};")
merge_table_query = f"""INSERT INTO {schema}.{table}
WITH numbered_data AS (
SELECT room_id, platform, service_type, title, floor, area, deposit, rent,
maintenance_fee, address, latitude, longitude, registration_number,
agency_name, agent_name, subway_count, nearest_subway_distance,
store_count, nearest_store_distance, cafe_count, nearest_cafe_distance,
market_count, nearest_market_distance, restaurant_count,
nearest_restaurant_distance, hospital_count, nearest_hospital_distance,
property_link, image_link,
ROW_NUMBER() OVER (PARTITION BY address, floor, deposit, rent, maintenance_fee ORDER BY room_id) AS rn
FROM (
SELECT room_id, platform, service_type, title, floor, area, deposit, rent,
maintenance_fee, address, latitude, longitude, registration_number,
agency_name, agent_name, subway_count, nearest_subway_distance,
store_count, nearest_store_distance, cafe_count, nearest_cafe_distance,
market_count, nearest_market_distance, restaurant_count,
nearest_restaurant_distance, hospital_count, nearest_hospital_distance,
property_link, image_link
FROM raw_data.zigbang
UNION ALL
SELECT room_id, platform, service_type, title, floor, area, deposit, rent,
maintenance_fee, address, latitude, longitude, registration_number,
agency_name, agent_name, subway_count, nearest_subway_distance,
store_count, nearest_store_distance, cafe_count, nearest_cafe_distance,
market_count, nearest_market_distance, restaurant_count,
nearest_restaurant_distance, hospital_count, nearest_hospital_distance,
property_link, image_link
FROM external_schema.dabang
)
)
SELECT room_id, platform, service_type, title, floor, area, deposit, rent,
maintenance_fee, address, latitude, longitude, registration_number,
agency_name, agent_name, subway_count, nearest_subway_distance,
store_count, nearest_store_distance, cafe_count, nearest_cafe_distance,
market_count, nearest_market_distance, restaurant_count,
nearest_restaurant_distance, hospital_count, nearest_hospital_distance,
property_link, image_link
FROM numbered_data
WHERE rn = 1;"""
cur.execute(merge_table_query)
cur.execute("COMMIT;")
except Exception as error:
print(error)
cur.execute("ROLLBACK;")
raise
dag = DAG(
dag_id = 'load_merge_table',
start_date = datetime(2024, 7, 1),
schedule = '@once',
catchup = False,
default_args = {
'retries': 0,
#'retry_delay': timedelta(minutes=3),
}
)
load_dabang_data = PythonOperator(
task_id = 'load_dabang_data',
python_callable = load_dabang_data,
params = {'url' : Variable.get("dabang_s3_url"),
'schema' : 'external_schema',
'table' : 'dabang'},
dag = dag
)
load_merge_table = PythonOperator(
task_id = 'load_merge_table',
python_callable = load_merge_table,
params = {'schema' : 'raw_data',
'table' : 'property'},
dag = dag
)
load_dabang_data >> load_merge_table내일 할 일
작성했던 DAG 구체화 : DAG, Task 이름 및 재시도 횟수, 재시도 지연 시간 등부동산 중개업자 데이터를 바로 RDS에 넣을 건지, Redshift -> RDS로 넣을 건지 회의
S3 -> Redshift : 부동산 중개업자 COPY 쿼리 작성 및 Airflow DAG로 작성S3 -> RDS : 방법 찾아보고 자동화를 위해 Airflow DAG로 작성
Redshift -> RDS로 테이블을 이동시키는 방법 찾아보기
2024-07-26 (금) 오늘 한 일
어제 작성했던 DAG 구체화 및 기능 추가
각 Task의 이름을 기능에 맞게 구체화 Redshift에서 RDS로 데이터를 복제하기 위해 S3에 UNLOAD 및 RDS 벌크 업데이트 Task 추가
추가된 두 개의 Task만 표시
현재 RDS 연결이 안 되어있기에 주석 처리 unload까지 정상 작동하는 것을 확인함
# 병합한 테이블(property)을 S3로 UNLOAD
def unload_merge_table(**context):
cur = get_redshift_conn()
schema = context["params"]["schema"]
table = context["params"]["table"]
uri = context["params"]["uri"]
iam_role = context["params"]["iam_role"]
try:
cur.execute("BEGIN;")
unload_query = f"""UNLOAD ('SELECT * FROM {schema}.{table}')
TO '{uri}'
IAM_ROLE '{iam_role}'
FORMAT AS PARQUET
ALLOWOVERWRITE
PARALLEL OFF;
"""
cur.execute(unload_query)
cur.execute("COMMIT;")
except Exception as error:
print(error)
cur.execute("ROLLBACK;")
raise
# load_merge_table_to_rds = S3ToMySqlOperator(
# task_id = 'load_merge_table_to_rds',
# s3_source_key = f"{Variable.get('unload_s3_uri')}000.parquet",
# mysql_table = 'property',
# mysql_duplicate_key_handling = 'IGNORE',
# mysql_extra_options = None,
# aws_conn_id = 's3_conn',
# mysql_conn_id = 'rds_conn',
# dag = dag
# )
load_dabang_data_to_external_from_s3 >> load_merge_table_with_dabang_and_zigbang >> unload_merge_table #>> load_merge_table_to_rds
S3의 부동산 중개업자 데이터를 Redshift 및 RDS로 적재하는 DAG 작성
S3에 적재하는 작업이 진행 중이기에 아직 테스트는 불가 S3에 적재하는 작업이 완료되면 하나의 DAG로 만들 예정
from airflow.providers.amazon.aws.transfers.s3_to_redshift import S3ToRedshiftOperator
from airflow.providers.mysql.transfers.s3_to_mysql import S3ToMySqlOperator
from airflow import DAG
from airflow.models import Variable
from datetime import datetime
from datetime import timedelta
dag = DAG(
dag_id = 'load_agent_data_to_redshift_and_rds',
start_date = datetime(2024, 7, 1),
schedule = '@once',
catchup = False,
default_args = {
'owner' : 'sangmin',
'retries' : 0,
# 'retry_delay': timedelta(minutes=1),
}
)
load_agent_data_to_redshift_from_s3 = S3ToRedshiftOperator(
task_id = "load_agent_data_to_redshift_from_s3",
s3_bucket = "team-ariel-1-bucket",
s3_key = Variable.get("agent_s3_uri"),
schema = "raw_data",
table = "agency_details",
copy_options=['csv'],
redshift_conn_id = "redshift_conn",
aws_conn_id = "s3_conn",
method = "REPLACE",
dag = dag
)
load_agent_data_to_rds_from_s3 = S3ToMySqlOperator(
task_id = 'load_agent_data_to_rds_from_s3',
s3_source_key = Variable.get("agent_s3_uri"),
mysql_table = 'property',
mysql_duplicate_key_handling = 'IGNORE',
mysql_extra_options = None,
aws_conn_id = 's3_conn',
mysql_conn_id = 'rds_conn',
dag = dag
)
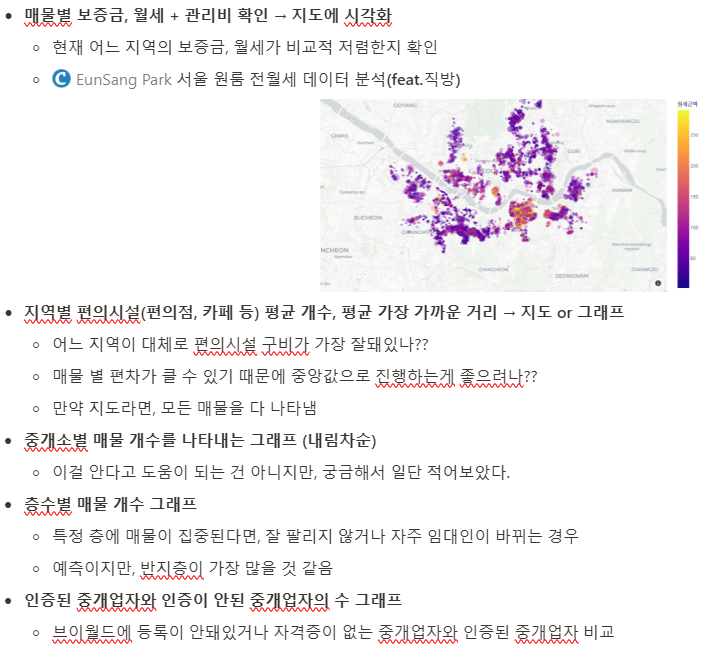
[load_agent_data_to_redshift_from_s3, load_agent_data_to_rds_from_s3]분석을 위해 생성할 테이블 탐색
내일(다음 주 월) 할 일
추가할 테이블 고려 및 어떤 테이블을 생성할 것인지 확정 분석 테이블 제작 or 웹 서비스 제작 도움
이번 주에 진행한 일, 다음 주에 진행할 일 이번 주에 진행한 일
AWS Glue, Redshift Spectrum 사용 여부 재검토 -> 사용 O raw_data ERD 확정 다방, 직방 데이터를 병합한 테이블을 만드는 DAG 작성
다방 (외부 테이블), 직방 (Redshift)를 불러와 UNION ALL, ROW_NUMBER 활용 Redshift -> S3 : S3에 Unload 하는 테스트 완료S3 -> RDS : 아직 RDS 연결이 안돼 테스트를 진행하지 못한 상황
분석을 위해 생성할 테이블 탐색
다음 주에 진행할 일
분석을 위해 생성할 테이블 탐색 및 확정
테이블 생성 DAG까지 작성 시간이 된다면 시각화까지 진행
S3 -> RDS로 벌크 업데이트하는 Task 테스트 진행 및 해당 DAG 작성 마무리 부동산 중개업자 데이터를 RDS, Redshift로 적재하는 DAG 작성 마무리
이 것은 다른 팀원과 함께하는 작업이기에 조율이 필요
가장 중요한 것은 웹 서비스 구현
필요하다면, 웹 서비스 제작을 도와 진행 분석 테이블 생성보다는 우선시해야 한다고 생각함