
이전에 Selenium을 배우고 나서 복습 겸 영화 사이트 스크래핑을 진행했었다. 이번에는 Django로 가져온 데이터를 웹으로 제공하는 프로젝트를 진행해보고자 한다. 계획서를 시작으로 기능을 하나씩 추가하여 완성도를 높일 것이다. 추가로 github 사용에 익숙해지기 위해 개인 프로젝트이지만, 최대한 활용해보려고 한다. 여유롭게 진행할 계획이고, 데브코스에서 다음 프로젝트가 진행되기 전(5/12) 까지 완료하는 것이 목표이다.
ss721229/competition-web
Contribute to ss721229/competition-web development by creating an account on GitHub.
github.com
프로젝트 계획
주제
여러 공모전 사이트(링커리어, 위비티 등)의 대회를 한 페이지에서 확인할 수 있는 웹 제작
활용 기술 및 프레임워크
- Frontend : html, css, javascript
- Backend : django, sqlite
- Crawling / Preprocessing : bs4, pandas
ERD(Entity Relationship Diagram) - DBdiagram
특별히 Primary Key로 설정할 요소가 보이지 않아 id를 pk로 지정하였다. 또한 공모전 플랫폼 별로 구분하여 제공할 것이기 때문에 platform 컬럼을 넣었으며, title / url / application_start / application_end는 사용자에게 제공할 정보이다.

기능
메인 페이지
- 검색 기능 : 공모전의 제목에 검색어가 포함되는 공모전을 찾아 제공
- 추천 검색어 : 빠른 검색을 위한 검색어 제공
- 더보기 기능 : 해당 플랫폼의 공모전을 추가로 확인하기 위한 더보기 링크 제공
세부 페이지 (1) - 검색
- 검색어에 부합하는 공모전을 사용자에게 제공
- 플랫폼, 제목, 접수 기간 정보를 제공
- 페이지네이션 기능 제공
세부 페이지 (2) - 더보기
- 선택한 플랫폼의 공모전을 사용자에게 제공
- 제목, 접수 기간 정보를 제공
- 페이지네이션 기능 제공
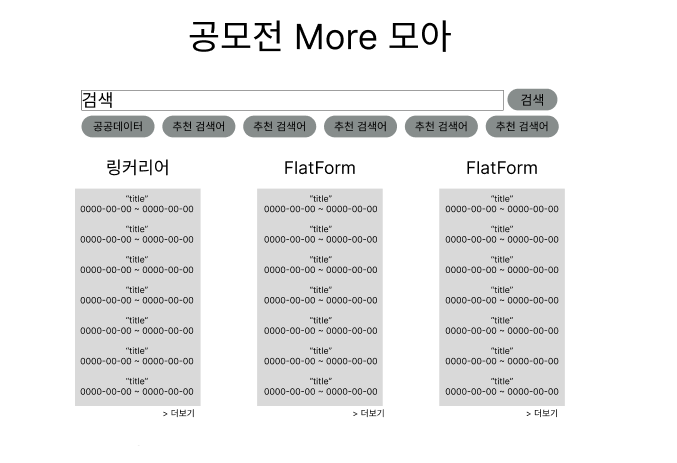
디자인 - Figma
디자인 감각은 없기 때문에 필요한 부분만 넣고 특별한 디자인은 하지 않았다. Figma도 처음 사용한 툴이기 때문에 접해본 것에 의의를 두었으며, 개발을 하다가 크기나 비율은 어느 정도 달라질 수 있을 것이다.
메인 페이지
세부 페이지


진행 프로세스
AWS나 Azure 같은 서비스를 이용하지 않고 로컬 시스템으로 장고 내부의 sqlite와 runserver를 활용할 것이다. 따라서 웹을 사용하기 전에 먼저 스크래핑을 통해 공모전 사이트에서 내용을 가져오는 작업을 실시해 준 후에 runserver 명령어로 서버를 실행시켜야 한다.

다음에는 프로젝트를 진행할 가상환경과 장고를 세팅하고, github와 연동하는 작업을 진행한다.
[개인 프로젝트] 공모전 크롤링 (2) - 가상환경 및 초기 설정, git remote
이전에 공모전 크롤링을 진행할 계획을 마련하였다. 이번에는 프로젝트를 진행할 가상환경과 장고를 세팅하고, github와 연동하는 작업을 진행한다. [개인 프로젝트] 공모전 크롤링 (1) - 계획서
sanseo.tistory.com
'프로젝트 단위 공부 > [개인 프로젝트] 공모전 크롤링' 카테고리의 다른 글
| [개인 프로젝트] 공모전 크롤링 (6) - 데이터 수집 (스크래핑) - 씽굿 (2) | 2024.05.01 |
|---|---|
| [개인 프로젝트] 공모전 크롤링 (5) - 데이터 수집 (스크래핑) - 위비티 (2) | 2024.05.01 |
| [개인 프로젝트] 공모전 크롤링 (4) - 데이터 수집 (스크래핑) - 링커리어 (0) | 2024.04.29 |
| [개인 프로젝트] 공모전 크롤링 (3) - mainpage (App 연동, Model 생성) (0) | 2024.04.27 |
| [개인 프로젝트] 공모전 크롤링 (2) - 가상환경 및 초기 설정, git remote (0) | 2024.04.27 |