
Amazon Redshift

Amazon Reshift란?
Redshift는 AWS에서 지원하는 완전 관리형 데이터 웨어하우스 서비스이다. PostgreSQL 기반으로 대규모 병렬 처리, 데이터 압축을 통해 효율적인 데이터 저장 및 최적의 쿼리 성능을 가져올 수 있다. 응답 속도보다 처리 용량에 최적화(OLAP)되어 있어 빠른 시간에 응답해야 한다면 사용하기 힘들다. 최근에는 Serverless로 가변 비용 서비스가 만들어졌다.
- OLAP(데이터 웨어하우스, ex - Redshift) vs OLTP(프로덕션 데이터베이스, ex - RDS)
- 고정 비용(ex - Redshift) vs 가변 비용(ex - Snowflake, BigQuery)
클러스터
클러스터는 리더 노드와 하나 이상의 컴퓨팅 노드로 구성되어 있다.

리더 노드 (Leader Node)
- 엔드포인트로써 클라이언트와 통신 처리 및 컴퓨팅 노드 관리
- 메타데이터를 저장하고 클러스터의 모든 쿼리 수행을 관리
컴퓨팅 노드 (Compute Node)
- 실제 작업을 수행하는 노드로 각 노드마다 여러 개의 슬라이스를 보유
- 병렬로 쿼리를 수행
- S3 기반으로 백업/복구 수행 가능
슬라이스 (Slice)
- 각 노드는 여러 개의 슬라이스로 구성
- 슬라이스는 별도의 메모리, CPU, 디스크 공간이 할당
- 슬라이스 별로 독립적인 워크 로드를 병렬적으로 수행
특징
대용량 병렬 처리(Massive Parallel Processing) - 분산형 시스템
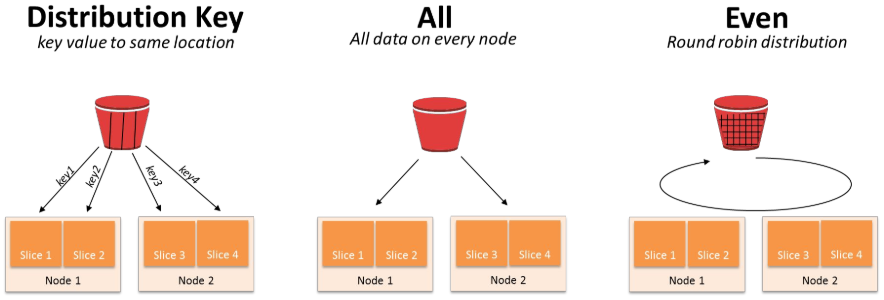
클러스터는 리더노드와 컴퓨팅 노드로 구성되어 있고, 컴퓨팅 노드는 하나 이상의 슬라이스로 구성되어 있다. 그리고 슬라이스에는 데이터가 포함된다. 고정 비용인 Redshift는 Compute Node를 추가로 생성하면, 레코드 분배 방식(Distkey, Diststyle, Sortkey)을 개발자가 적절히 설정해주어야 한다. 이와 다르게 가변 비용인 Snowflake와 BigQuery는 자동으로 구성되므로 신경 쓰지 않아도 된다.
- Distkey : 특정 컬럼의 값을 기준으로 분배, skew가 발생하지 않게 key를 잘 설정해야 함
- all : 모든 레코드가 모든 노드에 복제
- even(default) : round-robin 방식
컬럼 기반 스토리지
데이터베이스에 저장하는 방식이 레코드 별로 저장하는 것이 아니라 컬럼 별로 저장하며, 컬럼 별로 압축이 가능하다. 컬럼으로 압축함으로써 데이터를 읽는 크기를 줄이고 쿼리 성능을 향상할 수 있다. 따라서 추가할 레코드가 존재할 경우 데이터베이스에 레코드를 이어 붙이는 것이 아니라 COPY 명령어를 통해 모든 데이터를 다시 덮어쓰는 벌크 업데이트를 하는 것이 더 빠르고 효율적이다.
추가 자료
Redshift의 개념과 구조, 특징을 간단히 알아보았다. 이와 관련하여 데브코스에서 공부했던 내용을 링크로 첨부하였다. 데이터 웨어하우스, Redshift와 관련된 자세한 내용을 확인해 볼 수 있다.
- 데이터 웨어하우스, 데이터 레이크, ETL / ELT
- Redshift 소개(특징, 설치, 초기 설정, COPY 명령어)
- Redshift 고급 기능 실습(권한/보안, 백업/테이블 복구, 기타 서비스 소개 등)
- S3 -> Redshift 연동 및 COPY 명령어 실습
Reference
'Infra > AWS' 카테고리의 다른 글
| [AWS] Amazon VPC (Virtual Private Cloud) 개념과 구성 요소 (0) | 2024.07.03 |
|---|---|
| [AWS] AWS 서비스 종료 후에도 VPC 비용 발생 문제 해결 (0) | 2024.05.21 |
| [AWS] IAM 개념과 작동 방식 및 리소스 (0) | 2024.05.17 |
| [AWS] S3 데이터 적재 자동화(Amazon EC2, Crontab) (0) | 2024.05.16 |
| [AWS] Amazon S3 개념과 관련 용어 및 실습 (0) | 2024.05.15 |