
Redshift COPY 시 잘못된 timestamp 값이 적재되는 문제
Airflow의 S3ToOperator를 사용해 S3 버킷에 저장된 .parquet 파일을 Redshift에 COPY를 진행하였는데, 다른 모든 값은 모두 올바르게 적재되었음에도 timestamp 형식을 가진 컬럼만 잘못된 값이 적재되었다. 이 문제를 해결하기 위한 과정을 적어보려 한다.
데이터 처리 방식 (ETL)
우선 이슈가 발생했을 때의 S3에 적재되는 .parquet의 ETL 과정을 나타내 본 뒤 본격적으로 해결 과정을 알아보자.
데이터 추출 (Extract)
- 서울 도시데이터 API 호출을 통해 Json 형태의 데이터 추출
데이터 변형 (Transform)
- 추출한 데이터 (Json)를 가져와 필요한 데이터를 리스트 형태로 변경
- 여기서 리스트 하나의 요소는 dataframe으로 변형됐을 때의 하나의 행
- 참고 : ast.literal_eval 메서드를 사용해 Xcom의 데이터 (문자열)을 딕셔너리로 변경하여 진행
데이터 적재 (Load)
- 변형한 데이터 (List)를 가져와 DataFrame 형태로 변경해 S3 Load를 위한 작업 진행
- io.BytesIO 버퍼를 활용해 S3에 파일 저장 후 S3ToRedshiftOperator를 활용해 Redshift에 COPY
- 참고 : ast.literal_eval 메서드를 사용해 Xcom의 데이터 (문자열)을 리스트로 변경하여 진행
결과
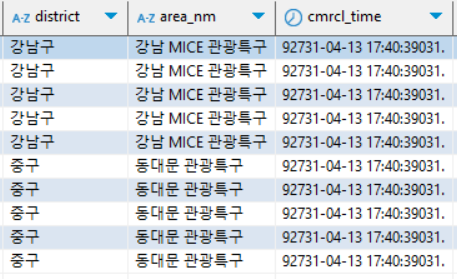
- 다음 사진과 같이 timestamp 형식을 가진 컬럼에서 잘못된 값이 적재된 것을 확인
- 그러나 S3에 저장 .parquet 파일 확인 결과 모든 값이 적절한 값이 적재돼 있었음
- 여기서 S3 Load까지는 문제가 없고 Redshift에 Load 시 문제가 발생함을 인지
문제 원인 파악 (feat. Redshift)
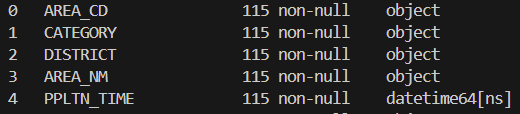
결론적으로는 Redshift가 나타내는 TIMESTAMP의 단위와 Pandas가 나타내는 단위가 달랐기 때문에 생긴 문제였다. 이러한 문제가 왜 발생하였는지 알아보자.
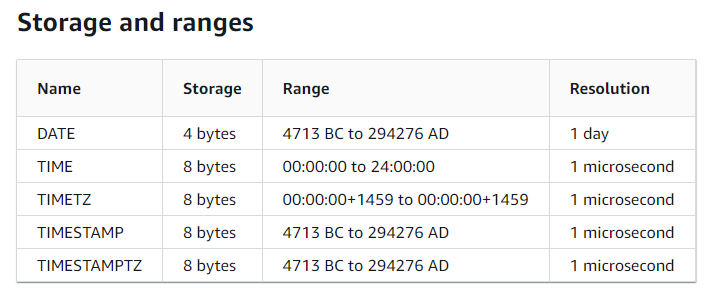
Redshift timestamp Resolution
Resolution은 쉽게 말해 해당 데이터 타입을 나타내는 단위라고 볼 수 있다. 예를 들어 DATE의 경우 Resolution이 1 day이므로 2024-01-01, 2024-01-02와 같이 하루 단위로 데이터를 나타내는 것이다. 여기서 중점적으로 봐야 할 것은 오류가 발생했던 TIMESTAMP 타입이다. TIMESTAMP의 Resolution은 1 ms로 설정되어 있음을 확인할 수 있다.
Pandas datetime Resolution
Pandas의 경우 Redshift와 달리 Resolution이 1 ns로 설정되어 있음을 확인할 수 있다.

결론
- Redshift[ms]와 Pandas[ns]는 timestamp를 다루는 단위가 달라 COPY로 적재를 할 때 에러가 발생
- ms는 10^-6, ns는 10^-9이기에 Redshift에 적재되면, 훨씬 큰 값이 나오는 것은 당연한 결과
문제 해결 (feat. pyarrow)
해결 전 S3 Load 코드
- io.BytesIO 버퍼를 사용해 전처리된 transformed_data를 버퍼에 대입
- s3_hook을 사용해 버퍼의 내용을 S3에 데이터 저장
- 문제점 : transformed_data는 Pandas DataFrame이기 때문에 Redshift와 timestamp Resolution이 다름
transformed_data = transform_data_type_for_load(transformed_data, file_name)
s3_hook = S3Hook(aws_conn_id="s3_conn")
parquet_buffer = io.BytesIO()
transformed_data.to_parquet(parquet_buffer, index=False)
s3_hook.load_bytes(
bytes_data=parquet_buffer.getvalue(),
bucket_name='popboard-s3-bucket',
key=f'{file_name}',
replace=True
)Pandas 내에서 ns -> ms 단위 변경 (실패)
pandas의 to_datetime 메서드의 인자로 unit을 사용하면 timestamp의 단위를 변경할 수 있다고 공식 문서에 명시되어 있다. 그러나 이 방식을 사용해 S3에 Load 후 .parquet 파일을 확인해 보면 다시 ns 단위로 변환되어 있었고, Redshift에도 같은 문제가 지속적으로 발생하였다.

transformed_data['cmrcl_time'] = pd.to_datetime(transformed_data['cmrcl_time'], unit='ms')Pyarrow 패키지를 활용해 ms로 변경해 데이터 저장 (성공)
Pyarrow 패키지를 활용하여 Pandas의 DataFrame을 Pyarrow Table로 변환시킨 뒤 버퍼에 timestamp를 ms로 변경한 값을 넣어주었다. coerce_timestamps 인자를 활용하면 timestamp 형태의 컬럼을 설정한 단위로 변경하여 저장할 수 있다.
import pyarrow.parquet as pq
import pyarrow as pa
transformed_data = pa.Table.from_pandas(transformed_data)
parquet_buffer = io.BytesIO()
pq.write_table(transformed_data, parquet_buffer, coerce_timestamps="ms")
Reference
https://pandas.pydata.org/docs/reference/api/pandas.to_datetime.html
https://docs.aws.amazon.com/redshift/latest/dg/r_Datetime_types.html
https://arrow.apache.org/docs/python/parquet.html#storing-timestamps
'Data Engineering > Airflow' 카테고리의 다른 글
| [Airflow] DAG를 선언하는 세 가지 방법 (0) | 2024.10.27 |
|---|---|
| [Airflow] DAG와 Task의 동시성을 관리하기 위한 변수 (0) | 2024.10.25 |
| [Airflow] DAG params를 PythonOperator 매개변수로 사용하기 (0) | 2024.10.15 |
| [Airflow] LocalExecutor Parallelism 개념 및 설정 방법 (0) | 2024.10.14 |
| [Airflow] Executor 실행 준비 과정 (SchedulerJobRunner._execute()) (0) | 2024.10.10 |