

연결 리스트(Linked Lists) (1)
추상적 자료구조(Abstract Data Structures)
- 내부 구현은 숨겨져 있는 상태로 사용하는 자료구조
- 데이터 : 정수, 문자열, 레코드 등
- 연산 : 삽입, 삭제, 순회, 정렬, 탐색 등
기본적 연결리스트
- 앞에 있는 노드가 뒤에 있는 노드를 가리키도록 되어있는 자료구조 형태
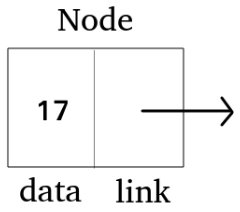
- 노드 : Data(문자열, 레코드, 또 다른 연결 리스트 등), Link (next)가 담김
- Head : 연결 리스트의 가장 앞의 노드를 가리키는 포인터
- Tail : 연결 리스트의 가장 마지막 노드를 가리키는 포인터

자료구조 정의
노드 클래스
class Node:
def __init__(self, item):
self.data = item
self.next = None연결리스트 클래스
class LinkedList:
def __init__(self):
self.nodeCount = 0
self.head = None
self.tail = None연산 정의
특정 원소 참조 (k 번째) - LinkedList 클래스의 메서드
def getAt(self, pos):
if pos <= 0 or pos > self.nodeCount:
return None
i = 1
curr = self.head
while i < pos:
curr = curr.next
i += 1길이 얻어내기 - LinkedList 클래스의 메서드
def getLen(self):
return self.nodeCount배열 vs 연결 리스트
- 원소 탐색에 대해 연결 리스트는 비효율적인 시간 복잡도를 보임
| 배열 | 연결 리스트 | |
| 저장 공간 | 연속한 위치 | 임의의 위치 |
| 특정 원소 지칭 | 매우 간편 | 선형탐색과 유사 |
| 시간 복잡도 | O(1) | O(n) |
실습
리스트 순회 - LinkedList 클래스의 메서드
def traverse(self):
if self.nodeCount == 0:
return []
l = []
curr = self.head
while curr != None:
l.append(curr.data)
curr = curr.next
return l연결 리스트(Linked Lists) (2)
연산 정의
원소 삽입 - LinkedList 클래스의 메서드
- 시간 복잡도: (1) 맨 앞, O(1) (2) 중간, O(n) (3) 맨 끝, O(1)
- 주의 사항 : (1) 삽입하려는 위치가 리스트 맨 앞일 때 (2) 삽입하려는 위치가 리스트 맨 끝일 때 (3) 빈 리스트에 삽입
def insertAt(self, pos, newNode):
if pos < 1 or pos > self.nodeCount + 1:
return False
if pos == 1:
newNode.next = self.head
self.head = newNode
else:
if pos == self.nodeCount + 1:
prev = self.tail
else:
prev = self.getAt(pos - 1)
newNode.next = prev.next
prev.next = newNode
if pos == self.nodeCount + 1:
self.tail = newNode
self.nodeCount += 1
return True두 리스트의 연결 - LinkedList 클래스의 메서드
- 리스트 L이 비어있을 경우를 위해 L.tail이 유효한지 검사를 하는 코드 존재
- self 리스트가 비어있을 경우를 위한 코드는 없어 오류 발생, 두 번째 코드는 이를 해결
def concat(self, L):
self.tail.next = L.head
if L.tail:
self.tail = L.tail
self.nodeCount += L.nodeCount# self 리스트가 비어있을 경우 오류 방지
def concat(self, L):
if self.nodeCount == 0:
self.head = L.head
self.tail = L.tail
else:
self.tail.next = L.head
if L.tail:
self.tail = L.tail
self.nodeCount += L.nodeCount실습
원소 삭제 - LinkedList 클래스의 메서드
- 시간 복잡도: (1) 맨 앞, O(1) (2) 중간, O(n) (3) 맨 끝, O(n)
- 주의 사항 : (1) 삭제하려는 위치가 리스트 맨 앞일 때 (2) 삭제하려는 위치가 리스트 맨 끝일 때 (3) 빈 리스트에 삽입
def popAt(self, pos):
if pos < 1 or pos > self.nodeCount:
raise IndexError # IndexError 발생
if self.nodeCount == 1:
curr = self.head
self.head, self.tail = None, None
elif pos == 1:
curr = self.head
self.head = curr.next
else:
prev = self.getAt(pos - 1)
curr = prev.next
prev.next = curr.next
if pos == self.nodeCount:
self.tail = prev
self.nodeCount -= 1
return curr.data연결 리스트(Linked Lists) (3)
연결리스트의 장점
- 삽입과 삭제가 유연하다는 것
변형된 연결리스트 및 연산
- 맨 앞에 dummy node(header)를 추가한 형태
변형된 연결리스트 클래스
class LinkedList:
def __init__(self):
self.nodeCount = 0
self.head = Node(None)
self.tail = None
self.head.next = self.tail리스트 순회
def traverse(self):
result = []
curr = self.head
while curr.next:
curr = curr.next
result.append(curr.data)
return result특정 원소 참조 (k 번째)
- pos가 0일 때, header를 반환
def getAt(self, pos):
if pos < 0 or pos > self.nodeCount:
return None
i = 0
curr = self.head
while i < pos:
curr = curr.next
i += 1
return currprev 다음 원소 삽입
def insertAfter(self, prev, newNode):
newNode.next = prev.next
if prev.next is None:
self.tail = newNode
prev.next = newNode
self.nodeCount += 1
return True원소 삽입
def insertAt(self, pos, newNode):
if pos < 1 or pos > self.nodeCount + 1:
return False
if pos != 1 and pos == self.nodeCount + 1:
prev = self.tail
else:
prev = self.getAt(pos - 1)
return self.insertAfter(prev, newNode)prev 다음 원소 삭제
def popAfter(self, prev):
if self.tail == prev:
return None
curr = prev.next
prev.next = curr.next
if self.tail == curr:
self.tail = prev
self.nodeCount -= 1
return curr.data원소 삭제
def popAt(self, pos):
if pos < 1 or pos > self.nodeCount:
raise IndexError
prev = self.getAt(pos - 1)
return self.popAfter(prev)두 리스트의 연결
def concat(self, L):
self.tail.next = L.head.next
if L.tail:
self.tail = L.tail
self.nodeCount += L.nodeCount양방향 연결 리스트(Doubly Linked Lists)
- 앞(다음 노드), 뒤(이전 노드) 모두 참조 가능한 연결 리스트

자료구조 정의
노드 클래스
class Node:
def __init__(self, item):
self.data = item
self.prev = None
self.next = None연결리스트 클래스
- 앞 뒤에 dummy node를 두고 뒤의 코드를 작성
class DoublyLinkedList:
self.nodeCount = 0
self.head = Node(None)
self.tail = None(None)
self.head.prev = None
self.head.next = self.tail
self.tail.prev = self.head
self.tail.next = None연산 정의
리스트 순회
def traverse(self):
result = []
curr = self.head
while curr.next.next:
curr = curr.next
result.append(curr.data)
return result리스트 역순회
def reverse(self):
result = []
curr = self.tail
while curr.prev.prev:
curr = curr.prev
result.append(curr.data)
return result특정 원소 참조 (k 번째)
- 찾아야 할 위치에 따라 head부터 찾을지, tail부터 찾을지 판단
def getAt(self, pos):
if pos < 0 or pos > self.nodeCount:
return None
if pos > self.nodeCount //2:
i = 0
curr = self.tail
while i < self.nodeCount - pos + 1:
curr = curr.prev
i += 1
else:
i = 0
curr = self.head
while i < pos:
curr = curr.next
i += 1
return curr
prev 다음 원소 삽입
def insertAfter(self, prev, newNode):
next = prev.next
newNode.prev = prev
newNode.next = next
prev.next = newNode
next.prev = newNode
self.nodeCount += 1
return True원소 삽입
def insertAt(self, pos, newNode):
if pos < 1 or pos > self.nodeCount + 1:
return False
prev = self.getAt(pos - 1)
return self.insertAfter(prev, newNode)실습
양방향 연결 리스트 역방향 순회
강의에서 해당 함수를 다뤘기 때문에 while이 아닌 for문과 nodeCount를 사용하여 역순회를 진행하였다.
def reverse(self):
result = []
curr = self.tail
for i in range(self.nodeCount):
curr = curr.prev
result.append(curr.data)
return result양방향 연결 리스트 노드 삽입
next 이전 노드에 newNode를 삽입하는 문제이다.
def insertBefore(self, next, newNode):
curr = next.prev
newNode.next = next
newNode.prev = curr
curr.next = newNode
next.prev = newNode
self.nodeCount += 1
return True양방향 연결 리스트 노드 삭제
prev 이후의 노드를 삭제하는 popAfter, next 이전의 노드를 삭제하는 popBefore, pos 위치의 노드를 삭제하는 popAt을 구현하는 문제이다.
def popAfter(self, prev):
if prev.next == self.tail:
return None
curr = prev.next
prev.next = curr.next
curr.next.prev = prev
self.nodeCount -= 1
return curr.datadef popBefore(self, next):
if next.prev == self.head:
return None
curr = next.prev
next.prev = curr.prev
curr.prev.next = next
self.nodeCount -= 1
return curr.datadef popAt(self, pos):
if pos < 1 or pos > self.nodeCount:
raise IndexError
return self.popAfter(self.getAt(pos - 1))양방향 연결 리스트의 병합
두 개의 연결 리스트를 병합하는 메서드 concat을 작성하는 문제이다. 마지막에 nodeCount를 안 더해줘서 계속 고민하고 있었다... ㅠㅠ
def concat(self, L):
prevTail = self.tail.prev
nextHead = L.head.next
prevTail.next = nextHead
nextHead.prev = prevTail
self.nodeCount += L.nodeCount
self.tail = L.tail스택(Stack)
- 자료를 보관할 수 있는 선형 구조
- 후입선출(LIFO) 구조로 push 연산과 pop 연산 존재
- 발생하는 오류 : 비어있는 스택에 pop(Stack Underflow), 가득 차있는 스택에 push(Stack Overflow)
배열을 이용하여 구현
- Python 리스트와 메서드 이용
- 스택을 간단하게 적용 가능
class ArrayStack:
def __init__(self):
self.data = []
# 스택의 원소의 수
def size(self):
return len(self.data)
# 스택이 비어 있는지 판단
def isEmpty(self):
return self.size() == 0
# 데이터 원소 추가
def push(self, item):
self.data.append(item)
# 마지막 데이터 원소 제거/반환
def pop(self):
return self.data.pop()
# 마지막 데이터 원소 반환
def peek(self):
return self.data[-1]연결 리스트를 이용하여 구현
- 위에 작성했던 양방향 연결 리스트 이용
from doublylinkedlist import Node
from doublylinkedlist import DoublyList
class ArrayStack:
def __init__(self):
self.data = DoublyLinkedList()
# 스택의 원소의 수
def size(self):
return self.data.getLength()
# 스택이 비어 있는지 판단
def isEmpty(self):
return self.size() == 0
# 데이터 원소 추가
def push(self, item):
node = Node(item)
self.data.insertAt(self.size() + 1, node)
# 마지막 데이터 원소 제거/반환
def pop(self):
return self.data.popAt(self.size())
# 마지막 데이터 원소 반환
def peek(self):
return self.data.getAt(self.size()).data수식의 괄호 유효성 검사
- 수식을 왼쪽부터 한 글자씩 읽음
- 여는 괄호 (, {, [를 만나면 스택에 푸시, 닫는 괄호 ), }, ]를 만나면 비어 있거나 스택의 괄호와 쌍이 맞지 않으면 False
- 끝까지 검사한 후 스택이 비어있어야 올바른 수식으로 판단
수식의 후위 표기법
- 중위 표기법 : 연산자가 피연산자들의 사이에 위치(ex. (A + B) * (C + D))
- 후위 표기법 : 연산자가 피연산자들의 뒤에 위치 (ex. AB+CD+*)
알고리즘
- 연산자의 우선순위 설정, prec = { '*' : 3, '/' : 3, '+' : 2, '-' : 2, '(' : 1}
- 중위 표현식을 왼쪽부터 한 글자씩 읽음
- 피연산자면 출력, '('이면 스택에 push, ')'이면 '('이 나올 때까지 스택에서 pop 및 출력
- 연산자면 스택에서 이보다 높거나 같은 우선순위인 것들을 pop 및 출력, 이 연산자는 스택에 push
- 모두 진행 후에 스택에 남아있는 연산자들은 모두 pop 및 출력
- 힌트 : peek()으로 우선순위 비교, while not opStack.isEmpty()로 남은 연산자 출력
실습
위의 알고리즘을 따라 중위 수식을 후위 수식으로 변환하는 문제이다.
def solution(S):
opStack = ArrayStack()
result = ''
for ch in S:
if ch.isupper():
result += ch
elif ch == '(':
opStack.push(ch)
elif ch == ')':
while True:
op = opStack.pop()
if op =='(':
break
result += op
else:
if opStack.isEmpty():
opStack.push(ch)
else:
while not opStack.isEmpty() and prec[opStack.peek()] >= prec[ch]:
result += opStack.pop()
opStack.push(ch)
while not opStack.isEmpty():
result += opStack.pop()
return result후위 표기 수식 계산
알고리즘
- 후위 표현식을 왼쪽부터 한 글자씩 읽음
- 연산자를 만나면 스택에서 pop을 두 번하여 (2) (연산자) (1)을 계산 및 스택에 push
- 수식의 끝에 도달하면 스택에서 pop - 계산 결과
실습
중위 수식을 후위 표기로 변환하여 계산 결과를 반환하도록 하는 문제였다. 여기서 splitTokens는 주어졌고, infixTopostfix와 postfixEval 함수를 작성하였다. infixTopostfix 함수는 위의 실습에서 문자열 형태를 리스트 형태로 바꾸어 작성하였다.
def splitTokens(exprStr):
tokens = []
val = 0
valProcessing = False
for c in exprStr:
if c == ' ':
continue
if c in '0123456789':
val = val * 10 + int(c)
valProcessing = True
else:
if valProcessing:
tokens.append(val)
val = 0
valProcessing = False
tokens.append(c)
if valProcessing:
tokens.append(val)
return tokens
def infixToPostfix(tokenList):
prec = {
'*': 3,
'/': 3,
'+': 2,
'-': 2,
'(': 1,
}
opStack = ArrayStack()
postfixList = []
for ch in tokenList:
if ch not in ['+','-','/','*','(',')']:
postfixList.append(ch)
elif ch == '(':
opStack.push(ch)
elif ch == ')':
while True:
op = opStack.pop()
if op =='(':
break
postfixList.append(op)
else:
if opStack.isEmpty():
opStack.push(ch)
else:
while not opStack.isEmpty() and prec[opStack.peek()] >= prec[ch]:
postfixList.append(opStack.pop())
opStack.push(ch)
while not opStack.isEmpty():
postfixList.append(opStack.pop())
return postfixList
def postfixEval(tokenList):
opStack = ArrayStack()
for data in tokenList:
if data == '+':
n1 = opStack.pop()
n2 = opStack.pop()
opStack.push(n2 + n1)
elif data == '-':
n1 = opStack.pop()
n2 = opStack.pop()
opStack.push(n2 - n1)
elif data == '/':
n1 = opStack.pop()
n2 = opStack.pop()
opStack.push(n2 / n1)
elif data == '*':
n1 = opStack.pop()
n2 = opStack.pop()
opStack.push(n2 * n1)
else:
opStack.push(data)
return opStack.pop()
def solution(expr):
tokens = splitTokens(expr)
postfix = infixToPostfix(tokens)
val = postfixEval(postfix)
return val결론
느낀 점
- 강의와 실습 문제를 모두 진행하는데 쉬는 시간 거의 없이 5시간 30분 걸림.. 힘들다...
- 연결리스트와 스택을 하루에 모두 이해하는 것이 사실 쉽지 않은데 많은 실습을 통해 도움이 됨
- 다룬 내용의 양이 엄청 방대하다보니 끝나고 나니 머리가 띵~
어려웠던 내용
- 파이썬을 사용하면서 클래스는 거의 다룬 적이 없는데, 해당 강의를 통해 클래스를 이해하는데 도움이 됨
참고링크
연결리스트 (Linked List)
https://velog.io/@dayon_log/%EC%97%B0%EA%B2%B0%EB%A6%AC%EC%8A%A4%ED%8A%B8-Linked-List
[자료구조 #5] 연결리스트(linked list)
https://bigbigpark.github.io/data_structure/linkedlist/
[Python 문법] 예외처리 (Exception)
'[프로그래머스] 데이터 엔지니어링 데브코스 3기 > TIL(Today I Learn)' 카테고리의 다른 글
| [TIL - 6일 차] 데이터 엔지니어링 : 파이썬으로 웹 데이터를 크롤하고 분석하기 (1) (2) | 2024.04.01 |
|---|---|
| [TIL - 5일 차] 데이터 엔지니어링 : 자료구조/알고리즘 풀기 (5) (0) | 2024.03.29 |
| [TIL - 4일 차] 데이터 엔지니어링 : 자료구조/알고리즘 풀기 (4) (0) | 2024.03.28 |
| [TIL - 3일 차] 데이터 엔지니어링 : 자료구조/알고리즘 풀기 (3) (2) | 2024.03.27 |
| [TIL - 1일 차] 데이터 엔지니어링 : 자료구조/알고리즘 풀기 (1) (0) | 2024.03.25 |