메타 데이터 DB를 주기적으로 백업해야 함, 특히 variables와 connections
airflow variables export variables.json
airflow connections export connections.json
가장 좋은 것은 메타 데이터 DB를 외부에 두는 것 (예 : AWS RDS)
Airflow와 같은 서버에 메타 데이터 DB가 있다면, DAG 등을 이용해 주기적으로 백업 실행
Health Check 모니터링
Airflow가 정상적으로 작동하는지 확인
webwerver, scheduler, 메타 데이터 DB 체크
Airflow 대안
Airflow 이외의 데이터 파이프라인 프레임워크
Prefect (Open Source)
Airflow와 상당히 흡사하며, 경량화된 버전
데이터 파이프라인을 동적으로 생성할 수 있는 강점
Dagster (Open Source)
데이터 파이프라인과 데이터를 동시에 관리
Learning Curve가 있고 결코 가벼운 툴이 아님
Airbyte (Open Source)
코딩을 최소화하여 Low-Code ETL 툴에 가까움
SaaS 형태 : FiveTran, Stitch Data, Segment
DBT (Data Build Tool)
Data Normalization
Analytics와 Analytics가 사용하는 데이터(raw_data) 사이에 큰 캡이 존재
해당 문제를 해결하기 위해 만들어진 것이 DBT
Data Normalization
데이터베이스를 더 조직적이고 일관된 방법으로 디자인하려는 방법
데이터베이스 정합성을 쉽게 유지하고 레코드를 수정 / 적재 / 삭제를 용이하게 하는 것
Normalization에서의 개념 : Primary Key, Composite Key, Foreign Key
Normal Form (NF)는 총 5단계까지 존재하지만, 3NF까지 알아보자
1NF (First Normal Form)
한 셀에는 하나의 값만 있어야 함 (atomicity)
Primary Key가 있어야 함
중복된 키나 레코드가 없어야 함
First Normal Form
2NF (Second Normal Form)
1NF 만족
Primary Key를 중심으로 의존 결과를 알 수 있어야 함
부분적인 의존도가 없어야 함, 즉 모든 부가 속성은 Primary Key로 찾을 수 있어야 함
Second Normal Form
3NF (Third Normal Form)
2NF 만족
전이적 부분 종속성이 없어야 함, 2NF의 그림에서는 state_code와 home_state가 같은 테이블에 존재
Third Normal Form
Slowly Changing Demensions (SCD)
DW나 DL에서는 모든 테이블의 히스토리를 유지하는 것이 중요
보통 두 개의 timestamp 필드를 갖는 것이 좋음
created_at : 생성 시간, 한 번 만들어지면 고정
updated_at : 마지막 수정 시간
SCD Type 0
한 번 쓰고 나면 바꿀 이유가 없고 히스토리와 관계가 없음
한 번 정해지면 갱신되지 않고 고정되는 필드
예시 : 고객 테이블의 회원 등록일, 제품 첫 구매일 등
SCD Type 1
데이터가 새로 생기면 덮어쓰면 되는 컬럼
처음 레코드 생성 시에는 존재하지 않았지만 나중에 채우는 경우
예시 : 고객 테이블의 연간 소득 필드
SCD Type 2
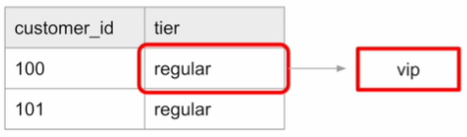
특정 Entity에 대한 데이터가 새로운 레코드로 추가
아래의 경우 '100, regular'와 '100, vip' 두 개의 레코드 존재
예시 : 고객 테이블에서 고객 등급의 변화
tier라는 컬럼의 값이 regular에서 vip로 변화
언제 승급을 한 것인지 확인할 수 있도록 변경 시간도 같이 추가
SCD Type 2
SCD Type 3
SCD Type 2처럼 레코드를 추가하는 것이 아닌 새로운 컬럼 추가
예시 : 고객 테이블에서 고객 등급의 변화
previous_tier라는 컬럼 생성
변경 시간도 별도 컬럼으로 존재해야 함
SCD Type 4
특정 Entity에 대한 데이터를 새로운 Dimension 테이블에 저장
DBT 소개
DBT
ELT용 오픈 소스 : In-warehouse Data Transformation
다양한 데이터 웨어하우스를 지원 : Redshift, Snowflake, BigQuery, Spark
클라우드 버전도 존재 : dbt Cloud
DBT 구성 컴포넌트
데이터 모델 (models)
테이블을 몇 개의 티어로 관리
Table, View, CTE 등
데이터 품질 검증 (tests)
스냅샷 (snapshots)
DBT 사용 시나리오
DBT 사용 목적
데이터 변경 사항을 이해하기 쉽고, 필요할 경우 Rollback 가능
데이터 간 리니지 확인 가능
데이터 품질 테스트 및 에러 보고
Fact 테이블의 증분 로드 (incremental Update)
Dimension 테이블 변경 추적 (히스토리 테이블)
용이한 문서 작성
Fact 테이블 vs Dimension 테이블
Fact 테이블 : 분석의 초점이 되는 양적 정보를 포함하는 중앙 테이블
일반적으로 매출 수익, 판매량, 이익과 같은 측정 항목을 포함하며 비즈니스 결정에 사용
외래 키를 통해 여러 Dimension 테이블과 연결됨
보통 Fact 테이블의 크기가 훨씬 더 큼
Dimension 테이블 : Fact 테이블에 대한 상세 정보를 제공하는 테이블
고객, 제품과 같은 테이블로 Fact 테이블에 대한 상세 정보 제공
Fact 테이블의 데이터에 맥락을 제공하여 다양한 방식으로 분석 가능하게 해 줌
Primary Key를 가지며, Fact 테이블에서 참조 (Foreign Key)
보통 Dimension 테이블의 크기는 훨씬 더 작음
Fact 테이블 vs Dimension 테이블
DBT 설치와 환경 설정
DBT 사용 절차
DBT 설치 : DBT Cloude vs DBT Core (Local)
DBT 환경 설정
Connector 설정
데이터 모델링 (tier)
테스트 코드 작성
필요에 따라 Snapshot 설정
DBT 설치 과정 (DBT Core)
dbt-redshift 패키지 설치
pip install dbt-redshift
dbt 환경 설정 : Redshift 정보 입력 (Host, ID/PW, Port 등), 해당 정보는 ~/.dbt/profiles.yml에 저장
dbt init learn_dbt
DBT Models : Input
프로세스
Model
ELT 테이블을 만듬에 있어 기본이 되는 빌딩 블록
테이블, 뷰, CTE의 형태로 존재
입력, 중간, 최종 테이블을 정의하는 곳 (tier : raw, staging, core 등)
Model 구성 요소
Input
입력(raw)과 중간(staging, src) 데이터 정의
raw는 CTE로 정의
staging은 View로 정의
Output
최종(core) 데이터 정의
core는 Table로 정의
Input과 Output은 models 폴더 밑에 sql 파일로 존재
View
SELECT 결과를 기반으로 만들어진 가상 테이블
CREATE VIEW 이름 AS SELECT ~
장점
데이터의 추상화 : 사용자는 View를 통해 필요 데이터에 직접 접근, 원본 데이터를 알 필요가 없음
데이터 보안 : View를 통해 사용자에게 필요한 데이터만 제공
복잡한 쿼리의 간소화 : SQL (View)을 사용하면 복잡한 쿼리를 단순화
단점
매번 쿼리가 실행되므로 시간이 걸림
원본 데이터의 변경을 모르면 실행이 실패
CTE (Common Table Expression)
WITH - AS 문을 활용해 같이 쓰이는 SELECT 문에서만 활용 후 사라짐
WITH temp1 AS (
SELECT k1, k2
FROM t1
JOIN t2 ON t1.id = t2.foreign_id
), temp2 AS (
…
)
SELECT *
FROM temp1 t1
JOIN temp2 t2 ON …
Model 빌딩
models/src/src_user_event.sql
WITH src_user_event AS (
SELECT * FROM raw_data.user_event
)
SELECT
user_id,
datestamp,
item_id,
clicked,
purchased,
paidamount
FROM
src_user_event
modes/src/src_user_variant.sql
WITH src_user_variant AS (
SELECT * FROM raw_data.user_variant
)
SELECT
user_id,
variant_id
FROM
src_user_variant
models/src/src_user_metadata.sql
WITH src_user_metadata AS (
SELECT * FROM raw_data.user_metadata
)
SELECT
user_id,
age,
gender,
updated_at
FROM
src_user_metadata
Model 빌딩 : 총 3개의 model 실행
dbt run
dbt run
DBT Models : Output
프로세스
Materialization
입력 데이터(테이블)를 연결해서 새로운 데이터(테이블)를 생성하는 것
파일이나 프로젝트 레벨에서 가능
4 가지의 내장 materialization이 제공
Materialization 종류
View : 데이터를 자주 사용하지 않는 경우
Table : 데이터를 반복해서 자주 사용하는 경우
Incremental : Fact 테이블, 과거 레코드를 수정할 필요가 없는 경우
Ephemeral (CTE) : 한 SELECT에서 자주 사용되는 데이터를 모듈화 하는 데 사용
Model 빌딩 (1)
Jinja Template과 ref 태그를 사용해 DBT 내 다른 테이블을 액세스
model/dim/dim_user_variant.sql
WITH src_user_variant AS (
SELECT * FROM {{ ref('src_user_variant') }}
)
SELECT
user_id,
variant_id
FROM
src_user_variant
model/dim/dim_user_metadata.sql
WITH src_user_metadata AS (
SELECT * FROM {{ ref('src_user_metadata') }}
)
SELECT
user_id,
age,
gender,
updated_at
FROM
src_user_metadata
model/fact/fact_user_event.sql (materialized = 'incremental') : WHERE문이 없으면 같은 레코드가 그만큼 중복
{{
config(
materialized = 'incremental',
on_schema_change='fail'
)
}}
WITH src_user_event AS (
SELECT * FROM {{ ref("src_user_event") }}
)
SELECT
user_id,
datestamp,
item_id,
clicked,
purchased,
paidamount
FROM
src_user_event
WHERE datestamp is not NULL
{% if is_incremental() %}
AND datestamp > (SELECT max(datestamp) from {{ this }})
{% endif %}
dbt_project.yml 수정 (1) : model의 materialized format 결정, 최종 Core 테이블은 view가 아닌 table로 빌드
models:
learn_dbt:
# Config indicated by + and applies to all files under models/example/
+materialized: view
dim:
+materialized: table
Model 빌딩 (1) : 총 6개의 model 실행
dbt run
dbt run
dbt_project.yml 수정 (2) : src 폴더의 model은 CTE로 설정
models:
learn_dbt:
# Config indicated by + and applies to all files under models/example/
+materialized: view
dim:
+materialized: table
src:
+materialized: ephemeral
Model 빌딩 (2) : 총 6개의 model을 찾음, 그러나 모델 빌딩은 3개만 진행
dbt run
dbt run
model 빌딩 (2)
models/dim/dim_user.sql
WITH um AS (
SELECT * FROM {{ ref("dim_user_metadata") }}
), uv AS (
SELECT * FROM {{ ref("dim_user_variant") }}
)
SELECT
uv.user_id,
uv.variant_id,
um.age,
um.gender
FROM uv
LEFT JOIN um ON uv.user_id = um.user_id
models/analytics/analytics/variant_user_daily.sql
WITH u AS (
SELECT * FROM {{ ref("dim_user") }}
), ue AS (
SELECT * FROM {{ ref("fact_user_event") }}
)
SELECT
variant_id,
ue.user_id,
datestamp,
age,
gender,
COUNT(DISTINCT item_id) num_of_items, -- 총 impression
COUNT(DISTINCT CASE WHEN clicked THEN item_id END) num_of_clicks, -- 총 click
SUM(purchased) num_of_purchases, -- 총 purchase
SUM(paidamount) revenue -- 총 revenue
FROM ue LEFT JOIN u ON ue.user_id = u.user_id
GROUP by 1, 2, 3, 4, 5
model 빌딩 : analytics_variant_user_daily가 view로 생성됨