
Spark Partition
Salting을 통한 Data Skew 처리
AQE가 등장하기 전 Data Skew 처리 방식 중 하나인 Salting에 대해 알아보자.
Partition 관련 환경 변수 (3.3.1)
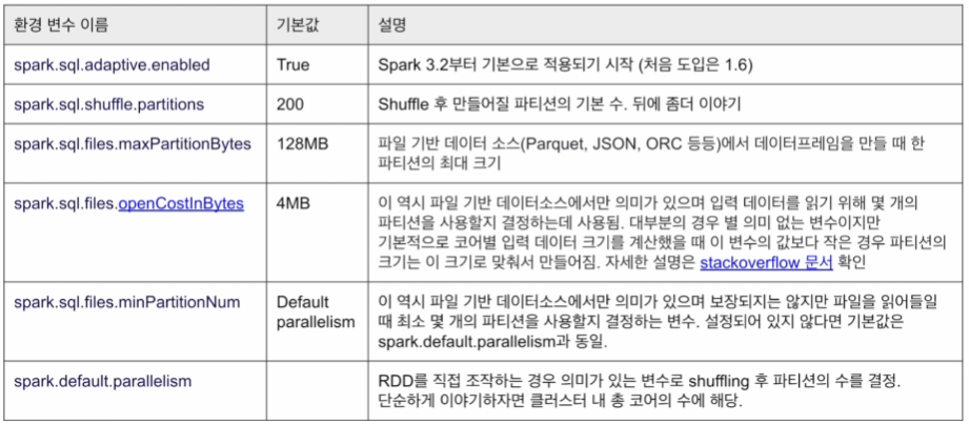
- spark.sql.shuffle.partitions
- 클러스터 차원과 처리 데이터의 크기를 고려하여 Job마다 바꿔 설정
- 큰 데이터를 처리한다면, 클러스터 전체 코어의 수로 설정
- AQE를 사용하는 관점에서는 조금 더 크게 설정하는 것이 좋음 (coalescing)
Salting
- Skew Partition을 처리하기 위한 테크닉
- AQE의 등장으로 인해 많이 쓰이지 않지만, AQE만으로 이슈가 사라지지 않는다면 필요할 수 있음
- 랜덤 필드를 만들고, 그 기준으로 Partition을 새로 만들어 처리
- Aggregation 처리의 경우 효과적
- Join의 경우 효과적이지 않음 -> Salting 테크닉을 일반화한 것이 AQE의 Skew Join 방식
Salting 예시 - Aggregation
- 요약
- 최종적인 실행 시간은 개선이 없거나 더 오래 걸림
- 그러나 Skew Partition으로 OOM과 같은 최악의 상황 방지
- item_id가 100인 데이터가 매우 많은 Skew된 Aggregation
SELECT item_id, COUNT(1)
FROM sales
GROUP BY 1
ORDER BY 2 DESC
LIMIT 100;- Salting 적용 : salt 필드 추가
- item_id로만 진행했을 때 Skew 발생하였기에 salt를 추가하여 Skew 방지
- 두 번의 Shuffling으로 시간은 더 오래 걸릴 수 있음
SELECT item_id, SUM(cnt)
FROM (
SELECT item_id, salt, COUNT(1) cnt
FROM (
SELECT FLOOR(RAND() * 200) salt, item_id
FROM sales
)
GROUP BY 1, 2
)
GROUP BY 1
ORDER BY 2 DESC
LIMIT 100;Salting 예시 - Skew JOIN (1)
- Skew JOIN은 AQE로 해결하는 것이 더 좋음, 여기서는 하는 방법만 알아보자!
- item_id가 100인 데이터가 매우 많은 Skew JOIN
SELECT date, sum(quantity * price) total_sales
FROM sales s
JOIN item i ON s.item_id = i.id
GROUP BY 1
ORDER BY 2 DESC;- Salting 적용 : salt 필드 추가
- Skew Partition이 있는 쪽에 salt 필드 추가
- 반대 Partition은 중복 레코드 생성 (EXPLODE)
SELECT date, sum(quantity * price) total_sales
FROM (
SELECT *, FLOOR(RAND() * 20) salt
FROM sales
) s
JOIN
SECLET *, EXPLODE(ARRAY(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19)) salt
FROM items
) i ON s.item_id = i.id and s.salt = i.salt
GROUP BY 1
ORDER BY 2 DECS;Salting 예시 - Skew JOIN (2)
- item_id가 100인 데이터가 Skew인 것을 알고 있을 때의 해결 방법
SELECT date, sum(quantity * price) AS total_sales
FROM (
SELECT *, CASE WHEN item_id = 100 THEN FLOOR(RAND() * 20) ELSE 1 END AS salt
FROM sales
) s
JOIN (
SECLET *, EXPLODE(ARRAY(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19)) salt
FROM items
WHERE id = 100
UNION
SELECT *, 1 salt
FROM items
WHERE id <> 100
) i ON s.item_id = i.id and s.salt = i.salt
GROUP BY 1
ORDER BY 2 DESC;Spill
- Partition의 크기가 너무 커서 메모리가 부족한 경우 디스크에 옮겨 적는 것
- 실행 시간이 늘어나고 OOM 발생 가능성 증가
- Spill 발생 원인
- Skew Partition의 Aggregation
- Skew Partition의 Join
- 굉장히 큰 Explode 작업
- 큰 Partition(spark.sql.files.maxPartitionBytes)이라면, 위의 작업 시 Spill 가능성이 높아짐
- Spill (Memory)
- 디스크로 Spill된 데이터가 메모리에 있을 때의 크기
- Deserialized 형태라 크기가 보통 8 - 10배 정도 더 큼
- Spill (Disk)
- 메모리에서 Spill된 데이터가 Disk에서 차지하는 크기
- Serialized 형태라 보통 크기가 훨씬 작음

입력 데이터를 로드할 때 Partition 수와 크기
입력 데이터를 로드할 때 Partition 수와 크기
- 기본적으로는 Partition의 최대 크기에 의해 결정
- spark.sql.files.maxpartitionbytes (default : 128MB)
- 압축 상태의 데이터를 기준으로 하기 때문에 크기가 더 커질 수 있음
- 해당 데이터가 어떻게 저장되었는지와 연관이 있음
- 파일 포맷, 압축 여부, 압축 방식 등
- Splittable 여부 확인 : 큰 파일을 Partition으로 나눠 로드할 수 있는가?

입력 데이터 Partition 수와 크기를 결정해 주는 변수
- bucketBy로 저장된 데이터를 읽는 경우
- Bucket 수와 Bucket 기준 컬럼, 정렬 기준 컬럼
- 읽어들이는 데이터 파일의 Splittable 여부
- Parquet/Avro 등은 항상 Splittable
- Json/csv 등의 경우도 레코드가 multi-line이면 Splittable하지 않음
- 입력 데이터의 전체 크기 (모든 파일 크기의 합)
- 입력 데이터를 구성하는 파일의 수
- Resource Manager에게 요청한 CPU 수
- 환경 변수
- spark.sql.files.maxPartitionBytes (128MB) : 하나의 Partition의 최대 크기
- spark.sql.files.openCostInBytes (4MB) : 입력 데이터 크기가 이 값보다 작으면, Partition의 크기로 설정
- spark.sql.files.minPartitionNum (parallelism) : 최소 몇 개의 Partition을 사용할지 결정
- spark.default.parallelism : 클러스터 내 총 코어의 수 (executor 수 * core 수)
Bucketing
- 데이터를 자주 사용되는 컬럼 기준으로 미리 저장해 두고 활용
- 다양한 최적화 가능
- 조인 대상 테이블이 Join Key를 갖고 Bucketing된 경우 Shuffle Free Join 가능
- 한쪽만 Bucketing 되어있는 경우 one-side Shuffle Free Join 가능
- Bucket Pruning을 통한 최적화 가능
- Shuffle Free Aggregation
- Bucket 정보가 메타스토어에 저장되고 Spark Compiler에서 활용
- sortBy를 통해 순서를 미리 정해주기도함
- Spark 테이블로 저장하고 로딩해야만 이 정보를 이용 가능 (saveAsTable(), spark.table())
- 예제 코드(Bucket 테이블 저장), 예제코드(Bucket 테이블 읽기)
Bucketing 저장 방식
- Bucket의 수 * Partition 수만큼의 파일이 만들어짐
- 예) DataFrame Partition 수가 10이고, Bucket 수가 4라면 40개의 파일 생성
- 다시 읽어 들일 때 10개의 Partition으로 읽힘
- Bucketing Key를 기반으로 작업 시 Shuffling이 없어짐 (Shuffle Free)
입력 데이터 Partition 수와 크기 결정 방식
- maxSplitBytes 결정 (spark maxSplitBytes)
- bytesPerCore = (데이터 파일의 전체 크기 + 파일 수 * OpenCostInBytes) / default.parallelism
- maxSplitBytes = Min(maxPartitionBytes, Max(bytesPerCore, OpenCostInBytes))
- bytesPerCore : CPU 하나가 처리해야 할 데이터의 크기
- maxSplitBytes = maxPartitionBytes : CPU 수보다 Partition 수가 더 많음
- maxSplitBytes = bytesPerCore : Partition 수를 CPU 수로 맞춤
- 입력 데이터를 구성하는 각 파일에 대해 다음을 진행
- Splittable하다면, maxSplitBytes 단위로 분할하여 File Chunk 생성
- Splittable하지 않거나 크기가 maxSplitBytes보다 작다면, 하나의 File chunk 생성
- File Chunk로부터 Partition 생성 (spark partition)
- 기본적으로 하나의 Partition은 하나 혹은 그 이상의 File Chunk로 구성
- 하나의 Partition에 (Next Chunk의 크기 + openCostInBytes) < maxSplitBytes를 넘기지 않도록 병합
입력 데이터를 로드할 때 Partition 수와 크기 결정 예시
예시 1 :입력 데이터 Partition 수와 크기 결정 (parquet)
- 파일 및 환경 변수 정보
- 파일 수 : 50
- 파일 포맷 : Parquet
- 파일 크기 : 65MB
- Spark Application에 할당된 Core 수 : 10
- spark.sql.files.maxPartitionBytes : 128MB
- spark.default.parallelism : 10
- spark.sql.files.openCostInBytes : 4MB
- Partition 수와 크기 결정
- bytesPerCore = (50 * 65 MB + 50 * 4MB) / 10 = 345MB
- maxSplitBytes = Min(128MB, 345MB) = 128MB
- 최종 Partition 수 : 50, 두 개의 파일이 Partition 하나에 못 들어감 (69MB = 65 + 4)
예시 2 :입력 데이터 Partition 수와 크기 결정 (parquet)
- 파일 및 환경 변수 정보
- 파일 수 : 50
- 파일 포맷 : Parquet
- 파일 크기 : 63MB
- Spark Application에 할당된 Core 수 : 10
- spark.sql.files.maxPartitionBytes : 128MB
- spark.default.parallelism : 10
- spark.sql.files.openCostInBytes : 4MB
- Partition 수와 크기 결정
- bytesPerCore = (50 * 63 MB + 50 * 4MB) / 10 = 345MB
- maxSplitBytes = Min(128MB, 335MB) = 128MB
- 최종 Partition 수 : 50, 두 개의 파일이 Partition 하나에 못 들어감 (67MB = 63 + 4)
예시 3 :입력 데이터 Partition 수와 크기 결정 (parquet)
- 파일 및 환경 변수 정보
- 파일 수 : 50
- 파일 포맷 : Parquet
- 파일 크기 : 40MB
- Spark Application에 할당된 Core 수 : 10
- spark.sql.files.maxPartitionBytes : 128MB
- spark.default.parallelism : 10
- spark.sql.files.openCostInBytes : 4MB
- Partition 수와 크기 결정
- bytesPerCore = (50 * 63 MB + 50 * 4MB) / 10 = 220MB
- maxSplitBytes = Min(128MB, 220MB) = 128MB
- 최종 Partition 수 : 17, Partition 하나에 세 개의 파일까지 들어감 (126MB = 40 * 3 + 4 * 2)
예시 4 :입력 데이터 Partition 수와 크기 결정 (csv)
- 파일 및 환경 변수 정보
- 파일 수 : 10
- 파일 포맷 : csv (Splittable하지 않음)
- 파일 크기 : 335MB
- Spark Application에 할당된 Core 수 : 10
- spark.sql.files.maxPartitionBytes : 128MB
- spark.default.parallelism : 10
- spark.sql.files.openCostInBytes : 4MB
- Partition 수와 크기 결정
- bytesPerCore = (10 * 335 MB + 10 * 4MB) / 10 = 339MB
- maxSplitBytes = Min(128MB, 339MB) = 128MB
- 최종 Partition 수 : 10, Split이 안되므로 128MB보다 크지만 하나씩 들어감 (339MB = 335 + 4)
예시 4 :입력 데이터 Partition 수와 크기 결정 (csv)
- 파일 및 환경 변수 정보
- 파일 수 : 100
- 파일 포맷 : csv (Splittable하지 않음)
- 파일 크기 : 10MB
- Spark Application에 할당된 Core 수 : 10
- spark.sql.files.maxPartitionBytes : 128MB
- spark.default.parallelism : 10
- spark.sql.files.openCostInBytes : 4MB
- Partition 수와 크기 결정
- bytesPerCore = (100 * 10 MB + 100 * 4MB) / 10 = 140MB
- maxSplitBytes = Min(128MB, 140MB) = 128MB
- 최종 Partition 수 : 12, Partition 하나에 9개의 파일까지 들어감 (124MB = 10 * 9 + 10 * 8)
요약
- 코어 별로 처리해야 할 크기가 너무 크다면 maxPartitionBytes로 제약
- 데이터의 크기가 적당하면 코어 수만큼 Partition 생성
- 데이터의 크기가 너무 작으면 openCostInBytes로 설정한 크기로 Partition 생성
Shuffling 후 만들어지는 Partition 수와 크기
- spark.sql.shuffle.partitions
- AQE와 Salting
- 이에 대한 내용은 TIL - 77일 차와 초반 내용을 참고
데이터를 저장할 때 Partition 수와 크기
데이터를 저장할 때 Partition 수와 크기
- 3가지 방식이 존재
- 기본
- bucketBy
- partitionBy
- 파일 크기를 레코드 수로도 제어 가능
- spark.sql.files.maxRecordsPerFile : default는 0이며, 레코드 수로 제약하지 않는다는 의미
데이터를 저장할 때 Partition 수와 크기 : 기본
- bucketBy, partitionBy를 사용하지 않는 경우
- 각 Partition이 하나의 파일로 쓰여짐
- saveAsTable vs save
- 적당한 크기와 수의 Partition을 찾는 것이 중요
- 작은 크기의 다수의 Partition이 있으면 문제
- 큰 크기의 소수의 Partition이 있으면 문제 (Splittable하지 않은 포맷으로 저장)
- Repartition, coalesce를 적절히 사용
- Parquet 포맷 사용
데이터를 저장할 때 Partition 수와 크기 : bucketBy
- 데이터 특성을 잘 아는 경우 특정 ID를 기준으로 나눠 테이블로 저장
- 이후에는 이를 로딩하여 사용함으로써 반복 처리 시 시간 단축
- 데이터의 특성을 잘 알고 있는 경우 사용 가능
- bucket의 수와 Key를 지정
- df.write.mode("overwrite").bucketBy(3, key).saveAsTable(table)
- sortBy를 사용해 순서를 정하기도 함
- 이 정보는 메타스토어에 같이 저장
CREATE TABLE bucketed_table (
id INT,
name STRING,
age INT
)
USING PARQUET
CLUSTERED BY (id)
INTO 4 BUCKETS;데이터를 저장할 때 Partition 수와 크기 : bucketBy
- 큰 로그 파일을 데이터 생성 시간을 기반으로 데이터 읽기를 많이 한다면?
- 데이터 자체를 연도-월-일의 폴더 구조로 저장 : 데이터 읽기/관리 최적화
- Partition Key를 잘못 지정하면 엄청 많은 파일이 생성됨
- Partition Key 지정
- df.write.mode("overwrite").partitionBy("order_month").saveAstable("order")
- df.write.mode("overwrite").partitionBy("year", "month", "day").saveAsTable("appl_stock")
CREATE TABLE partitioned_table (
id INT,
value STRING
) USING parquet
PARTITIONED BY (id);데이터를 저장할 때 Partition 수와 크기 : bucketBy & partitionBy
- partitionBy 후에 bucketBy 사용
- 필터링 패턴 기준 partitionBy 후 그루핑/조인 패턴 기준 bucketBy 사용
- df.write.mode("overwrite").partitionBy("dept").bucketBy(5, "employeeId")
Spark Persistent 테이블의 통계 정보 확인
- spark.sql("DESCRIBE EXTENDED Table_name") : bucket/partition 테이블 정보를 얻을 수 있음
- spark.sql("DESCRIBE EXTENDED appl_stock").show()

'[프로그래머스] 데이터 엔지니어링 데브코스 3기 > TIL(Today I Learn)' 카테고리의 다른 글
| [TIL - 1주차] 데브코스 최종 프로젝트 (0) | 2024.07.13 |
|---|---|
| [TIL - 80일 차] Spark, SparkML 실습 (5) (0) | 2024.07.12 |
| [TIL - 77일 차] Spark, SparkML 실습 (2) (0) | 2024.07.09 |
| [TIL - 76일 차] Spark, SparkML 실습 (1) (0) | 2024.07.08 |
| [TIL - 73일 차] 음식 배달에 걸리는 시간 예측하기 (2) (0) | 2024.07.03 |