TIL (2024-07-15 ~ 2024-07-19)
2024-07-15 (월)
주제 및 나의 역할
- 주제 : 조건 별 "원룸/투룸" 추천 웹 서비스
- 나의 역할 : ERD 설계 및 ELT
오늘 한 일


- 진행한 모델링
- 직방에서는 편의시설 정보를 따로 제공하지 않아 이에 대한 해결 방안을 찾아 스키마를 변경해야 함 (NearByFacilities)
- AgencyDetails 테이블은 찾은 csv 파일을 토대로 컬럼을 추가해야 함
(데이터 모델링은 처음 해봐서 걱정했는데, 팀원 분들이 나쁘지 않다고 하셔서 안도의 한숨을..)

고민 사항
- 편의시설 데이터를 어떻게 채워 넣을 것인가?
- 다방 : 크롤링을 통해 주변 편의시설의 상호명과 거리, 개수 등의 정보 추출 가능
- 직방 : 크롤링을 통해 가장 가까운 편의시설의 거리만 제공 (추가 데이터 수집 필요)
- 부동산 중개소 검색 API가 따로 없는데 어떻게 확인할 것인가?
- API 대신 브이월드에 매일 업데이트되는 부동산 중개소 정보 CSV 파일을 제공
- 테이블에 CSV 데이터를 저장한 뒤 부동산 중개소가 안전한지 확인
내일 할 일
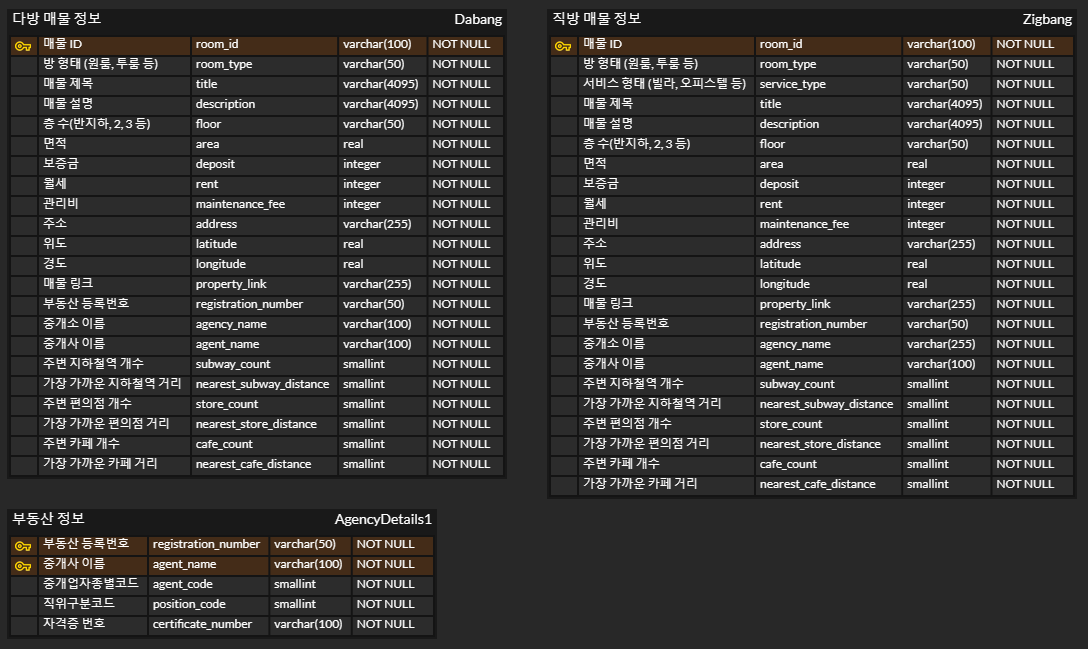
- 데이터 모델링 마무리 → 수정할 것 고치기
- AgencyDetails 컬럼 추가
- Rooms/NearByFacilities 테이블 제대로 만들기 → 특히 편의시설
- 직방/다방 데이터를 분리해서 관리할지, 합쳐서 관리할지 고민
- 등등
- 작성한 테이블 형태를 바탕으로 ERD 만들어서 공유
2024-07-16 (화)
오늘 한 일
- 데이터 모델링 1차 마무리 (erdcloud)
- 편의시설 테이블을 없애고 매물 정보에 병합
- 각 플랫폼 별로 테이블 분리 + 수정(컬럼 추가 및 삭제) -> 다방 or 직방
- CSV 데이터에 맞게 부동산 정보 추가
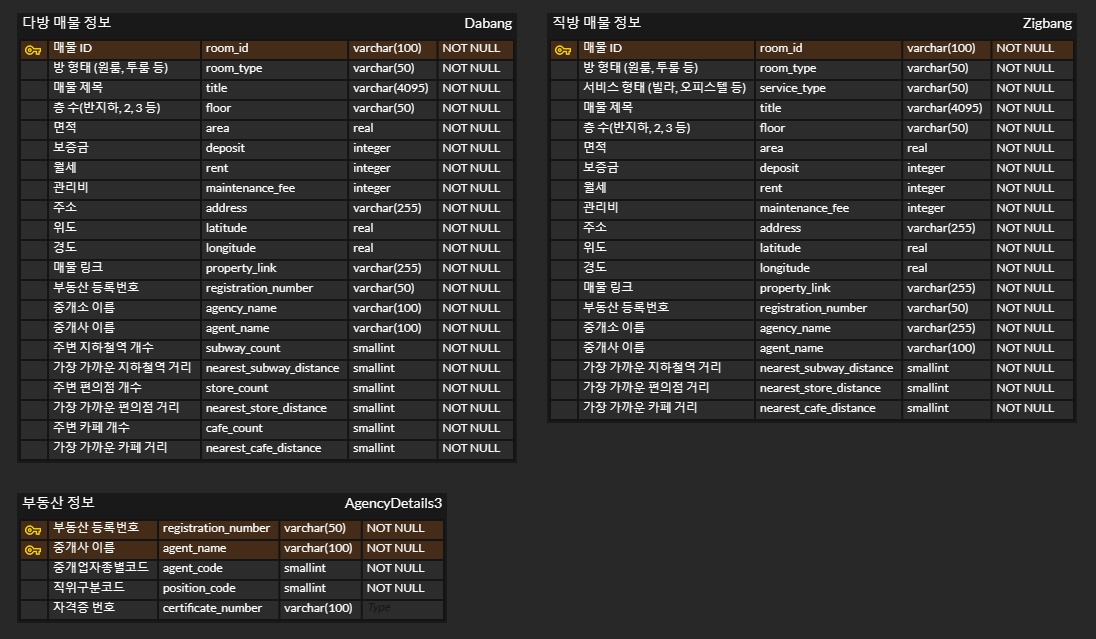
- 추가할 테이블
- 다방, 직방 테이블 JOIN 및 중복 제거된 테이블
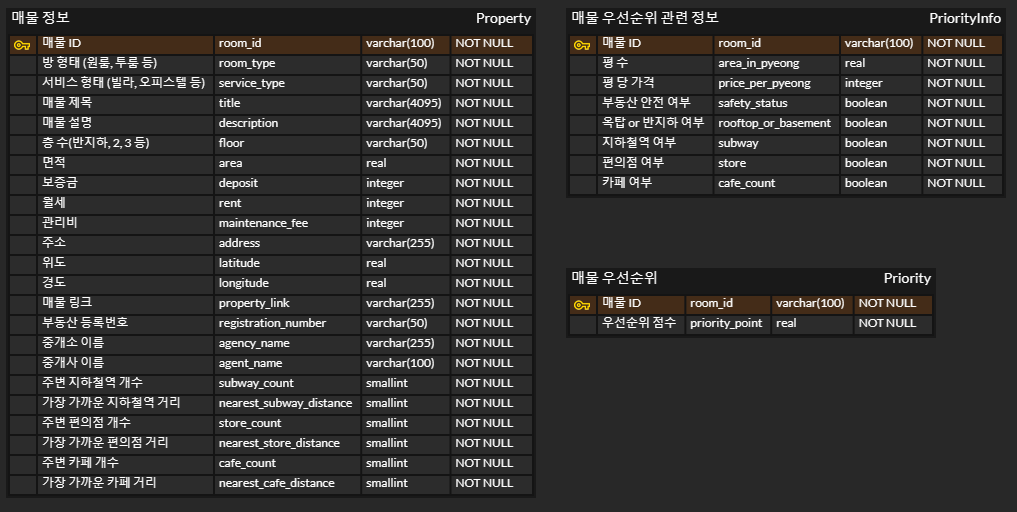
- 우선순위 정보 테이블 : 중복 제거된 테이블을 기반으로 제작
- 우선순위 점수 테이블 : 각 요소의 가중치를 조절하여 점수 부여
- 테이블 추가 및 구체화 필요

고민 사항
- 원천 데이터에 많은 데이터를 넣으면 좋은가?
- 이후에 테이블을 제작할 때, 많으면 많을수록 좋을 것 같긴 함
- 근데 많아지면 용량을 너무 많이 차지하지 않을까? 하는 우려
- DBT를 사용해야 하는가!!?
- 일단 테이블이 많지 않고, 관리하는데 무리가 없을 것 같음
- 조금 더 살펴보기로 하자
내일 할 일
- 추가할 테이블 생각해 보기
- 팀미팅 발표를 위한 전반적인 프로젝트 흐름 파악
2024-07-17 (수)
오늘 한 일
- ERD 수정 : 주변 편의시설은 카카오 API로 받아오는 걸로 결정

- Glue 공부 및 사용 여부 결정
- Glue 개념과 구성 요소
- 데브코스에서 Redshift Spectrum을 지원하지 않아 사용하지 않는 방향으로 갈 듯
- Athena는 대용량 데이터를 다룰 경우 비용 폭탄이 나와 사용 X
내일 할 일
- 회의를 통해 서비스 구체화 및 raw_data ERD 확정
- 확정된 ERD 토대로 Redshift에 데이터베이스 및 raw_data 테이블, 스키마 생성
2024-07-18 (목)
오늘 한 일
- 매물 추천 서비스 구체화
- 회의를 통해 사용자가 입력할 정보 및 제공받을 정보 구체화
- 공유 PPT 작업을 통해 웹 레이아웃을 간략하게 표현
- 회의 내용을 바탕으로 raw_data ERD 작업 마무리 및 Redshift 스키마 생성
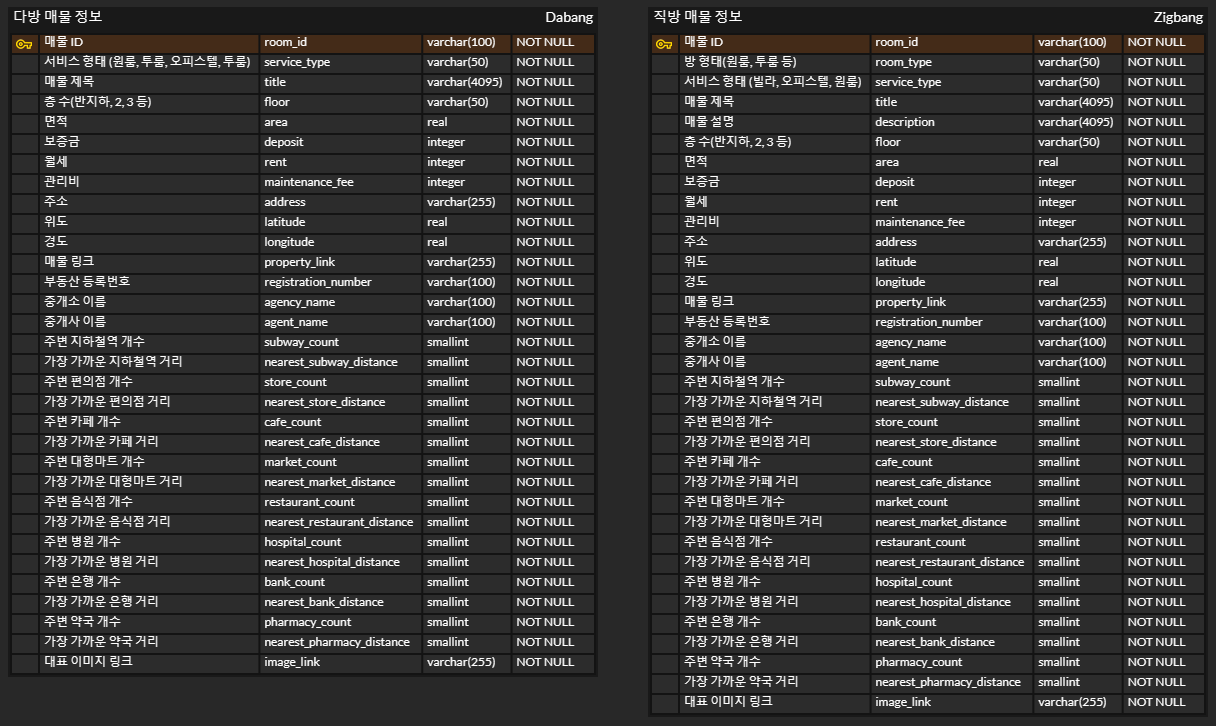
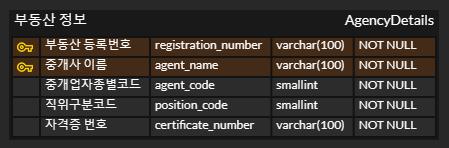
- 다방, 직방 데이터 JOIN 및 중복 제거 테이블
- 다양한 생각을 해보았지만, 아직 어떻게 같은 층의 매물을 구분할지 고민 중

- Redshift to RDS
- 웹 서비스를 RDS로 사용하기 위한 테이블을 생각해 봄
- 차후에 Redshift에서 RDS로 데이터를 옮기는 방법을 찾아야 할 듯
- S3 -> RDS, Redshift -> RDS 중 더 효율적인 방법으로 하면 될 듯
내일 할 일
- 다방, 직방 데이터 JOIN 및 중복 제거 테이블 매물 구분 조건 탐색 완료
- 샘플 데이터를 활용해 JOIN이 제대로 되는지 확인
2024-07-19 (금)
오늘 한 일
- 다방, 직방 병합 및 중복 제거된 테이블 생성
- 주소, 층으로 같은 건물의 같은 층까지는 구분 가능
- 만약 모든 조건이 동일한 매물이 존재한다면, 하나만 보여줘도 관계 X
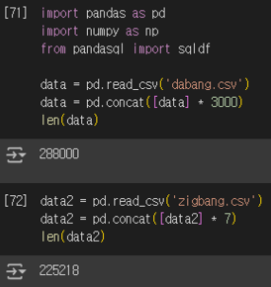
- 테이블 생성 과정 : pandasql 테스트 결과 22만 + 28만 레코드 처리 시 26초 정도 소요

CREATE TEMP TABLE temp_table AS
SELECT room_id, service_type, ~
FROM dabang
UNION ALL
SELECT room_id, service_type, ~
FROM zigbang
CREATE TABLE property AS
SELECT room_id, service_type, ~
FROM temp_table
GROUP BY address, floor, deposit, rent, maintenance_fee
- DBT 사용 여부 결정 : DBT는 사용하지 않고 프로젝트 진행

- 카카오 맵 API 호출 건 수 제한은 총 10만 번
- 약 4만 건의 매물에 대해 편의시설 정보(8번)를 호출해야 하므로 10만을 훌쩍 넘음
- 이를 해결하기 위해 이미 DB에 존재하면 데이터 수집을 진행하지 않도록 진행
- 아직 어떻게 할지 확정은 되지 않은 상태,
좋은 방법을 찾아야 할 텐데..
- 부동산 중개업자 정보 csv 파일 다운로드 자동화 (selenium)
- 파일 다운로드 버튼까지 클릭하도록 만듦 -> 로컬에 다운로드
- 해당 파일의 압축을 해제하고, S3에 저장하는 방법을 생각해야 함
내일(다음 주 월) 할 일
- 카카오 맵 API 호출 건 수 제한 문제를 해결하기 위한 방안 도출
- 부동산 중개업자 정보 csv 파일을 S3에 적재할 수 있도록 코드 작성
이번 주에 진행한 일, 다음 주에 진행할 일
이번 주에 진행한 일 (7/15 ~ 7/19)
- 서비스 구체화 및 직방, 다방, 부동산 데이터(raw_data)에 대한 ERD 작성
- 직방, 다방 데이터를 병합(UNION ALL) 및 중복 제거 테이블 생성을 위한 쿼리 작성
- AWS Glue, dbt 사용 여부 : 모두 사용하지 않는 것으로 결정
다음 주에 진행할 일 (7/22 ~ 7/26)
- AWS Spectrum 지원이 추가되어 AWS Glue 사용 여부 재검토 필요
- 부동산 중개업자 정보 csv 파일을 S3에 적재할 수 있도록 코드 작성
- Redshift의 다방, 직방 데이터로 병합 및 중복 제거 테이블을 생성 (ELT)하는 Airflow DAG 작성
