
이전에 mainpage app 생성 및 로컬 페이지에서 접속 가능하도록 코드를 작성하였고, ERD를 바탕으로 models를 생성하였다. 이번에는 스크래핑을 통해 데이터 수집을 진행할 것이다. 여러 개의 사이트 중 오늘은 링커리어 스크래핑을 진행한다.
[개인 프로젝트] 공모전 크롤링 (3) - mainpage (App 연동, Model 생성)
이전에 가상환경과 장고 프로젝트 생성까지 완료하였다. 이번에는 mainpage App을 구축하고 ERD를 토대로 Model migraion을 진행할 것이다. [개인 프로젝트] 공모전 크롤링 (2) - 가상환경 및 초기 설정, g
sanseo.tistory.com
변경 사항
모델 수정
platform(50 -> 100)과 title(100 -> 200)의 max_length를 여유롭게 수정하고, url을 CharField에서 URLField로 변경하였다. URLField가 따로 있는지 몰랐는데, ChatGPT를 사용하면서 알게 되었다. 그리고 D-Day나 기업명 등 다양한 정보를 추가하고자 하는 생각이 있었지만, 프로젝트의 목적은 공부이기에 원래 구상했던 요소만 사용하여 진행하려고 한다.
from django.db import models
# Create your models here.
class Competition(models.Model):
platform = models.CharField(max_length=100)
title = models.CharField(max_length=200)
url = models.URLField()
application_start = models.DateTimeField()
application_end = models.DateTimeField()프레임워크
원래 bs4의 beautifulsoup 라이브러리를 사용하여 스크래핑을 진행하려고 하였다. 그런데 링커리어 사이트가 동적 웹으로 구성되어 있기에 beautifulsoup을 사용할 수가 없었다. 따라서 동적 웹을 스크래핑할 수 있는 selenium 라이브러리를 활용하여 진행하였다. 그러나 속도는 beautifulsoup가 빠르기에 가능하다면 다른 사이트에서는 bs4를 사용할 예정이다. 동적 웹과 정적 웹의 차이를 보려면 아래를 참고하면 된다.
[Web/Python] 동적(Dynamic)/정적(Static) 수집 방법 비교
서론 BeautifulSoup과 Selenium은 웹 스크래핑/크롤링하는 데 사용되는 Python 라이브러리이다. 두 개 모두 웹 페이지 정보를 얻기 위해 사용되는데, 언제 BeautifulSoup/Selenium을 사용해야 하는지 판단하기
sanseo.tistory.com
selenium 설치
pip install selenium데이터 수집 - 링커리어
링커리어 LINKareer | 대외활동 공모전 대학생 인턴 대기업 채용정보
대기업 채용, 인턴, 대학생 대외활동, 공모전, 동아리 등 개인에게 맞춤화된 커리어 정보를 추천받으세요! 커뮤니티에서 고민을 나누고, 인턴 및 신입 합격 후기도 확인 할 수 있습니다. 관심 있
linkareer.com
링커리어 링크 및 목록 형태
링크
링크는 아래와 같다. 페이지네이션이 적용되어 있으며, f"~?page={i}"의 형태로 반목분 탐색을 할 수 있을 것이다.

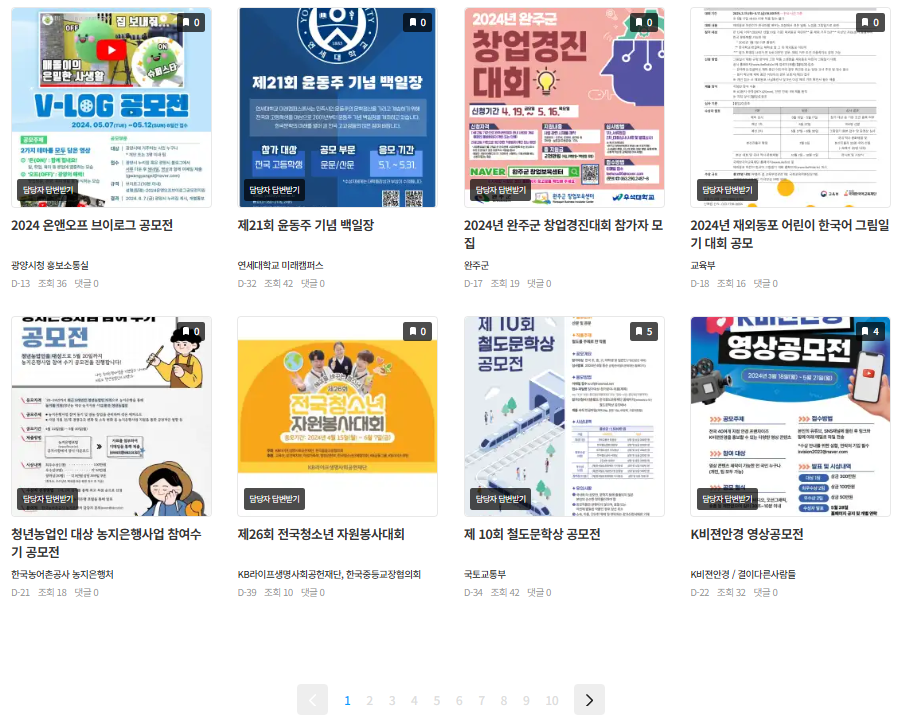
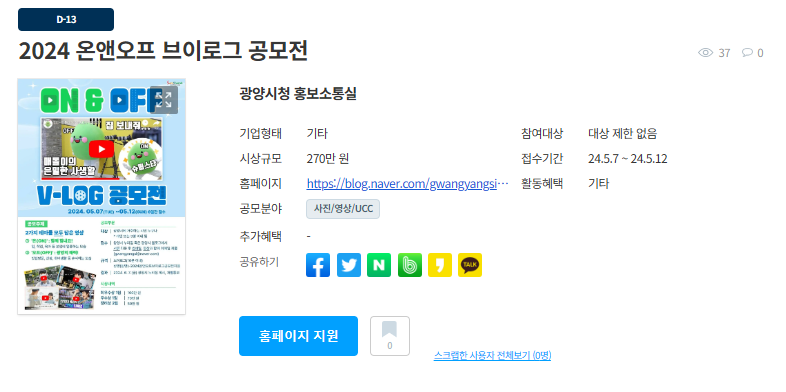
페이지
페이지의 일부를 캡쳐한 것이다. 제목은 바깥에서 확인이 가능하지만, 세부 정보(공모전 시작 날짜, 종료 날짜)는 페이지에 접속해야 알 수 있으므로 하나씩 접속하는 과정을 거쳐야 한다.
반복문 종료 기준
마지막 페이지까지 스크래핑을 진행하였다면, 반복문을 종료할 수 있도록 초과하는 페이지의 특징을 살펴보았다. 공모전이 존재하지 않는 페이지에서는 다음과 같은 문구와 함께 "search-result" 클래스가 존재한다.


코드
스크래핑(scraping_linkcarrer.py)
마지막 페이지를 구분하여 반복문을 종료하거나 세부 정보를 가져오기 위한 코드 등을 작성하면서 여러 시행착오를 겪긴 했지만.. 다음과 같이 코드가 작성되었다. 마지막 페이지임을 구분하는 코드인 try-except 구문에서 find_element는 찾는 요소가 없다면 NoSuchElementException 에러를 발생시키는 것을 이용해 마지막 페이지에 종료될 수 있도록 하였다.
사실 스크래핑 작업은 관리자 도구를 살펴보고 원하는 요소를 추출하는 작업이기에 특별히 코드 설명을 자세히 하지 않도록 하겠다. 아래 코드의 로직은 해당 페이지에서 'title'과 'url'을 가져오고, 해당 페이지에 존재하는 공모전의 세부 페이지에 접속해 'application_start'와 'application_end'를 가져오는 것이다.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from save import save_data_to_database
def scraping_linkcarrer():
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
page_number = 1
title, url, application_start, application_end = [], [], [], []
while page_number:
driver.implicitly_wait(10)
driver.get(f"https://linkareer.com/list/contest?page={page_number}")
try:
driver.find_element(By.CLASS_NAME, "search-result")
print(f"모든 페이지 스크래핑 완료")
break
except NoSuchElementException:
print(f"{page_number} 페이지 스크래핑 시작")
titles = driver.find_elements(By.CLASS_NAME, "activity-title")
urls = driver.find_elements(By.CLASS_NAME, "image-link")
for t in titles:
title.append(t.text)
for u in urls:
href = u.get_attribute("href")
url.append(href)
for u in url:
driver.get(u)
driver.implicitly_wait(5)
date = driver.find_elements(By.TAG_NAME, "h3")
if date[3].text != "-":
application_start.append(date[3].text.split(' ')[0])
application_end.append(date[3].text.split(' ')[2])
else:
application_start.append(None)
application_end(None)
print(f"{page_number} 페이지 스크래핑 완료")
page_number += 1
driver.quit()
return title, url, application_start, application_end데이터베이스에 저장(save.py)
모델에 접근하기 위해서는 환경변수를 설정하고, setup을 실행해주어야 한다. 최상단에 실행해야 하며, 특히 3-4줄 코드가 실행된 후에 models가 import 되어야 한다. import 순서는 중요하지 않은 줄 알고 에러 해결하다가 시간을 좀 많이 썼다.. 다른 사이트 스크래핑 데이터도 하나의 함수로 저장 작업을 진행할 수 있도록 다른 파일을 통해 작성하였다.
import os
import django
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'moremore.settings')
django.setup()
from datetime import datetime
from mainpage.models import Competition
def save_data_to_database(platform, title, url, application_start, application_end):
for t, u, start, end in zip(title, url, application_start, application_end):
Competition.objects.create(
platform=platform,
title=t,
url=u,
application_start=datetime.strptime(start, "%y.%m.%d").strftime("%Y-%m-%d"),
application_end=datetime.strptime(end,"%y.%m.%d").strftime("%Y-%m-%d")
)git push
git add .
git commit -m "feat: add scraping linkcarrer, save functions and change model"
git push origin main다음에는 다른 공모전 사이트인 위비티의 데이터를 스크래핑하고 저장하는 작업을 진행한다.
[개인 프로젝트] 공모전 크롤링 (5) - 데이터 수집 (스크래핑) - 위비티
이전에 모델의 url을 URLField로 수정하고, 링커리어의 데이터를 스크래핑하고 저장하는 작업을 하였다. 이번에는 다른 공모전 사이트인 위비티의 데이터를 스크래핑하고 저장하는 작업을 진행한
sanseo.tistory.com
'프로젝트 단위 공부 > [개인 프로젝트] 공모전 크롤링' 카테고리의 다른 글
| [개인 프로젝트] 공모전 크롤링 (6) - 데이터 수집 (스크래핑) - 씽굿 (2) | 2024.05.01 |
|---|---|
| [개인 프로젝트] 공모전 크롤링 (5) - 데이터 수집 (스크래핑) - 위비티 (2) | 2024.05.01 |
| [개인 프로젝트] 공모전 크롤링 (3) - mainpage (App 연동, Model 생성) (0) | 2024.04.27 |
| [개인 프로젝트] 공모전 크롤링 (2) - 가상환경 및 초기 설정, git remote (0) | 2024.04.27 |
| [개인 프로젝트] 공모전 크롤링 (1) - 계획서 (0) | 2024.04.25 |