
이전에 모델의 url을 URLField로 수정하고, 링커리어의 데이터를 스크래핑하고 저장하는 작업을 하였다. 이번에는 다른 공모전 사이트인 위비티의 데이터를 스크래핑하고 저장하는 작업을 진행한다.
[개인 프로젝트] 공모전 크롤링 (4) - 데이터 수집 (스크래핑) - 링커리어
이전에 mainpage app 생성 및 로컬 페이지에서 접속 가능하도록 코드를 작성하였고, ERD를 바탕으로 models를 생성하였다. 이번에는 스크래핑을 통해 데이터 수집을 진행할 것이다. 여러 개의 사이트
sanseo.tistory.com
데이터 수집 - 위비티
링커리어 페이지는 동적 웹 페이지였기 때문에 불가피하게 selenium을 사용하여 스크래핑을 진행하였다. 그러나 위비티는 정적 웹 페이지이기 때문에 속도가 더 빠른 Beautifulsoup 라이브러리를 사용하여 스크래핑을 진행한다.
공모전 대외활동 - 위비티
대학생 공모전 사이트 대외활동 서포터즈 모집 추천 아이디어 마케팅 광고 일러스트 디자인 웹툰 만화 미술 사진 소설 문학 시 ucc 영상 창업 경진대회
www.wevity.com
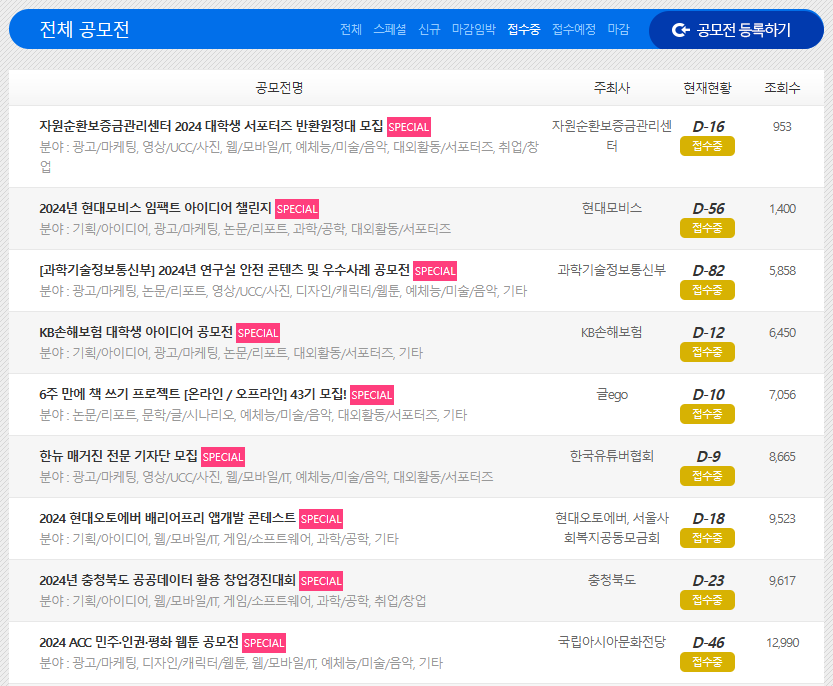
위비티 링크 및 목록 형태
링크
접수 중인 공모전만 표시하도록 하는 링크 형태이다. 페이지네이션이 적용돼 있고, f"~/?c=find&s=1&mode=ing&gp={i}"의 형태로 반복문 탐색을 할 수 있을 것이다.

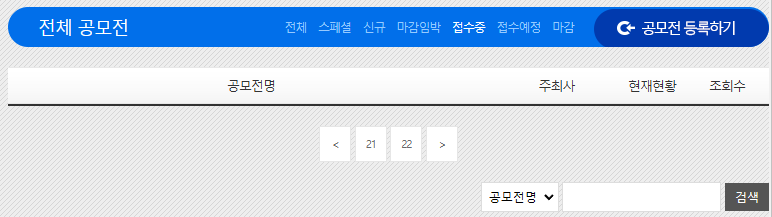
페이지
페이지의 일부를 캡쳐한 것이다. 링커리어와 마찬가지로 제목은 바깥에서 확인이 가능하지만, 세부 정보(공모전 시작 날짜, 종료 날짜)는 페이지에 접속해야 알 수 있다.


반복문 종료 기준
beautifulsoup를 사용하므로 find / find_all 메서드를 사용해 필요한 요소를 찾는데, find_all을 사용하였을 때 검색한 요소가 존재하지 않으면 빈 리스트를 반환하게 된다. 아래와 같이 페이지를 넘어가게 되면 공모전이 뜨지 않으므로 이를 활용하여 빈 리스트가 반환될 경우 종료하도록 하면 된다.
코드
스크래핑(scraping_linkcarrer.py)
링커리어와 유사한 형태의 코드로 작성하였다. 달라진 것은 html 형태에 따른 요소 추출 방법과 라이브러리이다. 필요한 요소(제목 등)를 추출할 때, 필요 없는 요소인 'span' 태그 내부의 텍스트가 존재했기 때문에 이를 제외하기 위한 코드가 작성된 부분 이외에는 특별한 부분은 없다.
from bs4 import BeautifulSoup
import requests
import time
from save import save_data_to_database
def scraping_wevity():
page_number = 1
title, url, application_start, application_end = [], [], [], []
while page_number:
response = requests.get(f"https://www.wevity.com/?c=find&s=1&mode=ing&gp={page_number}")
soup = BeautifulSoup(response.text, 'html.parser')
element_tit = soup.find_all(class_="tit")[1:]
if len(element_tit) == 0:
print(f"모든 페이지 스크래핑 완료")
break
print(f"{page_number} 페이지 스크래핑 시작")
for e in element_tit:
text = ''
for element in e.find('a').contents:
if element.name == 'span':
continue
text += str(element).strip()
title.append(text)
url.append('https://www.wevity.com/' + (e.find('a').get('href')))
for u in url:
time.sleep(0.3)
response = requests.get(u)
soup = BeautifulSoup(response.text, 'html.parser')
element_dday_area = soup.find_all('li', class_="dday-area")
for e in element_dday_area:
text = ''
for element in e.contents:
if element.name == 'span':
continue
text += str(element).strip()
application_start.append(text.split(' ')[0])
application_end.append(text.split(' ')[2])
time.sleep(0.3)
print(f"{page_number} 페이지 스크래핑 완료")
page_number += 1
return title, url, application_start, application_end
if __name__ == "__main__":
title, url, application_start, application_end = scraping_wevity()
save_data_to_database('위비티', title, url, application_start, application_end)데이터베이스에 저장(save.py)
이전에 작성했던 save.py에 if-elif 구문을 추가해 platform 별로 저장하도록 하였다. platform, title, url 저장 방식은 똑같지만, 날짜 형식이 다르기 때문에 구분하여 데이터베이스에 저장되도록 작성하였다.
import os
import django
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'moremore.settings')
django.setup()
from datetime import datetime
from mainpage.models import Competition
def save_data_to_database(platform, title, url, application_start, application_end):
if platform == '링커리어':
for t, u, start, end in zip(title, url, application_start, application_end):
Competition.objects.create(
platform=platform,
title=t,
url=u,
application_start=datetime.strptime(start, "%y.%m.%d").strftime("%Y-%m-%d"),
application_end=datetime.strptime(end,"%y.%m.%d").strftime("%Y-%m-%d")
)
elif platform == '위비티':
for t, u, start, end in zip(title, url, application_start, application_end):
Competition.objects.create(
platform=platform,
title=t,
url=u,
application_start=datetime.strptime(start,'%Y-%m-%d'),
application_end=datetime.strptime(end,'%Y-%m-%d')
)git push
git add .
git commit -m "feat: add scraping wevity, modify save functions to save wevity data"
git push origin main다음에는 마지막 사이트인 씽굿을 스크래핑하고 저장하는 작업을 진행할 것이다.
[개인 프로젝트] 공모전 크롤링 (6) - 데이터 수집 (스크래핑) - 씽굿
이전에 위비티 사이트를 스크래핑하고 데이터를 저장하는 작업을 진행하였다. 마지막으로 씽굿을 스크래핑하고 저장하는 작업을 진행할 것이다. [개인 프로젝트] 공모전 크롤링 (5) - 데이터 수
sanseo.tistory.com
'프로젝트 단위 공부 > [개인 프로젝트] 공모전 크롤링' 카테고리의 다른 글
| [개인 프로젝트] 공모전 크롤링 (7) - 메인 페이지 (프론트) (2) | 2024.05.02 |
|---|---|
| [개인 프로젝트] 공모전 크롤링 (6) - 데이터 수집 (스크래핑) - 씽굿 (2) | 2024.05.01 |
| [개인 프로젝트] 공모전 크롤링 (4) - 데이터 수집 (스크래핑) - 링커리어 (0) | 2024.04.29 |
| [개인 프로젝트] 공모전 크롤링 (3) - mainpage (App 연동, Model 생성) (0) | 2024.04.27 |
| [개인 프로젝트] 공모전 크롤링 (2) - 가상환경 및 초기 설정, git remote (1) | 2024.04.27 |
이전에 모델의 url을 URLField로 수정하고, 링커리어의 데이터를 스크래핑하고 저장하는 작업을 하였다. 이번에는 다른 공모전 사이트인 위비티의 데이터를 스크래핑하고 저장하는 작업을 진행한다.
[개인 프로젝트] 공모전 크롤링 (4) - 데이터 수집 (스크래핑) - 링커리어
이전에 mainpage app 생성 및 로컬 페이지에서 접속 가능하도록 코드를 작성하였고, ERD를 바탕으로 models를 생성하였다. 이번에는 스크래핑을 통해 데이터 수집을 진행할 것이다. 여러 개의 사이트
sanseo.tistory.com
데이터 수집 - 위비티
링커리어 페이지는 동적 웹 페이지였기 때문에 불가피하게 selenium을 사용하여 스크래핑을 진행하였다. 그러나 위비티는 정적 웹 페이지이기 때문에 속도가 더 빠른 Beautifulsoup 라이브러리를 사용하여 스크래핑을 진행한다.
공모전 대외활동 - 위비티
대학생 공모전 사이트 대외활동 서포터즈 모집 추천 아이디어 마케팅 광고 일러스트 디자인 웹툰 만화 미술 사진 소설 문학 시 ucc 영상 창업 경진대회
www.wevity.com
위비티 링크 및 목록 형태
링크
접수 중인 공모전만 표시하도록 하는 링크 형태이다. 페이지네이션이 적용돼 있고, f"~/?c=find&s=1&mode=ing&gp={i}"의 형태로 반복문 탐색을 할 수 있을 것이다.
페이지
페이지의 일부를 캡쳐한 것이다. 링커리어와 마찬가지로 제목은 바깥에서 확인이 가능하지만, 세부 정보(공모전 시작 날짜, 종료 날짜)는 페이지에 접속해야 알 수 있다.
반복문 종료 기준
beautifulsoup를 사용하므로 find / find_all 메서드를 사용해 필요한 요소를 찾는데, find_all을 사용하였을 때 검색한 요소가 존재하지 않으면 빈 리스트를 반환하게 된다. 아래와 같이 페이지를 넘어가게 되면 공모전이 뜨지 않으므로 이를 활용하여 빈 리스트가 반환될 경우 종료하도록 하면 된다.
코드
스크래핑(scraping_linkcarrer.py)
링커리어와 유사한 형태의 코드로 작성하였다. 달라진 것은 html 형태에 따른 요소 추출 방법과 라이브러리이다. 필요한 요소(제목 등)를 추출할 때, 필요 없는 요소인 'span' 태그 내부의 텍스트가 존재했기 때문에 이를 제외하기 위한 코드가 작성된 부분 이외에는 특별한 부분은 없다.
from bs4 import BeautifulSoup
import requests
import time
from save import save_data_to_database
def scraping_wevity():
page_number = 1
title, url, application_start, application_end = [], [], [], []
while page_number:
response = requests.get(f"https://www.wevity.com/?c=find&s=1&mode=ing&gp={page_number}")
soup = BeautifulSoup(response.text, 'html.parser')
element_tit = soup.find_all(class_="tit")[1:]
if len(element_tit) == 0:
print(f"모든 페이지 스크래핑 완료")
break
print(f"{page_number} 페이지 스크래핑 시작")
for e in element_tit:
text = ''
for element in e.find('a').contents:
if element.name == 'span':
continue
text += str(element).strip()
title.append(text)
url.append('https://www.wevity.com/' + (e.find('a').get('href')))
for u in url:
time.sleep(0.3)
response = requests.get(u)
soup = BeautifulSoup(response.text, 'html.parser')
element_dday_area = soup.find_all('li', class_="dday-area")
for e in element_dday_area:
text = ''
for element in e.contents:
if element.name == 'span':
continue
text += str(element).strip()
application_start.append(text.split(' ')[0])
application_end.append(text.split(' ')[2])
time.sleep(0.3)
print(f"{page_number} 페이지 스크래핑 완료")
page_number += 1
return title, url, application_start, application_end
if __name__ == "__main__":
title, url, application_start, application_end = scraping_wevity()
save_data_to_database('위비티', title, url, application_start, application_end)데이터베이스에 저장(save.py)
이전에 작성했던 save.py에 if-elif 구문을 추가해 platform 별로 저장하도록 하였다. platform, title, url 저장 방식은 똑같지만, 날짜 형식이 다르기 때문에 구분하여 데이터베이스에 저장되도록 작성하였다.
import os
import django
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'moremore.settings')
django.setup()
from datetime import datetime
from mainpage.models import Competition
def save_data_to_database(platform, title, url, application_start, application_end):
if platform == '링커리어':
for t, u, start, end in zip(title, url, application_start, application_end):
Competition.objects.create(
platform=platform,
title=t,
url=u,
application_start=datetime.strptime(start, "%y.%m.%d").strftime("%Y-%m-%d"),
application_end=datetime.strptime(end,"%y.%m.%d").strftime("%Y-%m-%d")
)
elif platform == '위비티':
for t, u, start, end in zip(title, url, application_start, application_end):
Competition.objects.create(
platform=platform,
title=t,
url=u,
application_start=datetime.strptime(start,'%Y-%m-%d'),
application_end=datetime.strptime(end,'%Y-%m-%d')
)git push
git add .
git commit -m "feat: add scraping wevity, modify save functions to save wevity data"
git push origin main다음에는 마지막 사이트인 씽굿을 스크래핑하고 저장하는 작업을 진행할 것이다.
[개인 프로젝트] 공모전 크롤링 (6) - 데이터 수집 (스크래핑) - 씽굿
이전에 위비티 사이트를 스크래핑하고 데이터를 저장하는 작업을 진행하였다. 마지막으로 씽굿을 스크래핑하고 저장하는 작업을 진행할 것이다. [개인 프로젝트] 공모전 크롤링 (5) - 데이터 수
sanseo.tistory.com
'프로젝트 단위 공부 > [개인 프로젝트] 공모전 크롤링' 카테고리의 다른 글
| [개인 프로젝트] 공모전 크롤링 (7) - 메인 페이지 (프론트) (2) | 2024.05.02 |
|---|---|
| [개인 프로젝트] 공모전 크롤링 (6) - 데이터 수집 (스크래핑) - 씽굿 (2) | 2024.05.01 |
| [개인 프로젝트] 공모전 크롤링 (4) - 데이터 수집 (스크래핑) - 링커리어 (0) | 2024.04.29 |
| [개인 프로젝트] 공모전 크롤링 (3) - mainpage (App 연동, Model 생성) (0) | 2024.04.27 |
| [개인 프로젝트] 공모전 크롤링 (2) - 가상환경 및 초기 설정, git remote (1) | 2024.04.27 |