
mau_summary, channel_summery를 config로 옮기기
아래 링크의 'ELT 구현'을 확인해 보면 nps_summary.py를 예시로 config에 대한 이해를 할 수 있다. nps_summary의 형태를 참고하여 mau_summary, channel_summary를 작성해 보자. nps_summary에서는 input_check, output_check를 통해 테스트가 추가되어 있는데, 해당 부분은 제외하고 필요한 부분만 작성할 것이다.
[TIL - 51일 차] Airflow 고급기능과 DBT, 데이터 디스커버리 (1)
ELT 작성과 슬랙 연동Docker 기반 Airflow 실행이전에 사용했던 airflow의 docker-compose.yaml의 x-airflow-common과 airflow-init을 수정하여 사용한다.environmentAIRFLOW_VAR_DATA_DIRAIRFLOW_VAR_ : 해당 문자 뒤에 나오는 문
sanseo.tistory.com
config/mau_summary.py
input_check와 output_check는 사용하지 않을 것이기 때문에 아예 지웠다가 redshift_summary Operator의 __init__을 실행하던 중 에러가 발생하였다. 그래서 빈 리스트 형태로 적어주었다.
{
'table': 'mau_summary',
'schema': 'ss721229',
'main_sql': """
SELECT
TO_CHAR(A.ts, 'YYYY-MM') AS month,
COUNT(DISTINCT B.userid) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1;""",
'input_check': [],
'output_check': []
}config/channel_summary.py
{
'table': 'channel_summary',
'schema': 'ss721229',
'main_sql': """
SELECT
DISTINCT A.userid,
FIRST_VALUE(A.channel) over(partition by A.userid order by B.ts rows between unbounded preceding and unbounded following) AS First_Channel,
LAST_VALUE(A.channel) over(partition by A.userid order by B.ts rows between unbounded preceding and unbounded following) AS Last_Channel
FROM raw_data.user_session_channel A
LEFT JOIN raw_data.session_timestamp B ON A.sessionid = B.sessionid;""",
'input_check': [],
'output_check': []
}Build_summary_v2.py
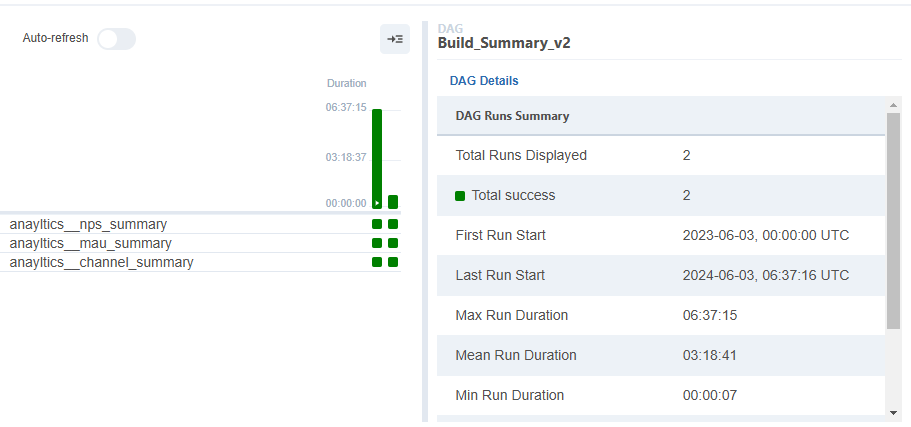
작성돼 있던 Build_summary_v2의 tables_load에 mau_summary, channel_summary를 추가해 주었다.
...
# this should be listed in dependency order (all in analytics)
tables_load = [
'nps_summary',
'mau_summary',
'channel_summary'
]
dag_root_path = os.path.dirname(os.path.abspath(__file__))
redshift_summary.build_summary_table(dag_root_path, dag, tables_load, "redshift_dev_db")결과
'[프로그래머스] 데이터 엔지니어링 데브코스 3기 > 숙제' 카테고리의 다른 글
| [숙제 - 79일 차] 타이베이 주택 가격 예측 모델 만들기 with Spark ML (2) | 2024.07.12 |
|---|---|
| [숙제 - 52일 차] 활성화된 DAG 찾기, config API 활성화, variables API (0) | 2024.06.04 |
| [숙제 - 43일 차] airflow.cfg 관련 문제 해결 (0) | 2024.05.22 |
| [숙제 - 41일 차] 데이터 파이프라인 실습 코드 문제점 해결하기 (0) | 2024.05.20 |
| [숙제 - 33일 차] S3 -> Redshift, COPY 명령어로 데이터 적재하기 (2) (0) | 2024.05.09 |