타이베이 주택 가격 예측 모델 만들기 타이베이 주택 가격 예측 모델 만들기
Colab Spark 환경 설정 라이브러리 설치 !pip install pyspark==3.3.1 py4j==0.10.9.5Spark Session 생성
Local Standalone Spark 사용
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Taipei Housing Price Prediction") \
.getOrCreate()
모델 빌딩 데이터 가져오기
S3에 저장된 Taipei_sindan_housing.csv를 가져옴
!wget https://~/Taipei_sindan_housing.csv데이터 읽기
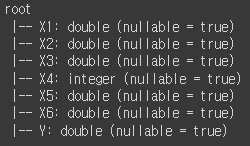
csv 파일을 읽은 뒤 Schema와 데이터 20개를 확인
data = spark.read.csv('./Taipei_sindan_housing.csv', header=True, inferSchema=True)
data.printSchema()
data.show()
데이터 벡터화
학습을 위해 학습에 사용할 피쳐를 벡터화하여 새로운 컬럼 생성
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(inputCols=['X1', 'X2', 'X3', 'X4', 'X5', 'X6'], outputCol='features')
data_vec = assembler.transform(data)모델 빌딩 및 예측
LinearRegression을 사용해 모델 빌딩 및 예측
from pyspark.ml.regression import LinearRegression
train, test = data_vec.randomSplit([0.8, 0.2], seed=1234)
lr = LinearRegression(featuresCol='features', labelCol='Y')
model = lr.fit(train)
pred = model.transform(test)
pred.select(['Y', 'prediction']).show()
RMSE 확인 from pyspark.ml.evaluation import RegressionEvaluator
evaluator = RegressionEvaluator(labelCol='Y', predictionCol='prediction', metricName='rmse')
rmse = evaluator.evaluate(pred)
print(rmse)