
빅데이터 처리와 Spark 소개
빅데이터와 대용량 분산 시스템
빅데이터 정의
- 서버 한대로 처리할 수 없는 규모의 데이터
- 기존의 소프트웨어로는 처리할 수 없는 규모의 데이터
- 4V
- Volume : 데이터의 크기
- Velocity : 데이터의 처리 속도
- Variaty : 구조화 / 비구조화 데이터
- Veracity : 데이터의 품질
빅데이터의 예
- 디바이스 데이터 : 모바일, 스마트 TV, 각종 센서 (IoT) 데이터, 네트워킹 디바이스 등
- 웹
- 수십 조개 이상의 웹 페이지 존재 -> 지식의 바다
- 웹 검색엔진 개발은 진정한 대용량 데이터 처리
- 사용자 검색어와 클릭 정보 자체도 대용량
- 요즘 웹 개발 자체가 NLP 거대 모델 개발의 훈련 데이터로 사용
빅데이터 처리의 특징과 해결방안
- 스토리지
- 큰 데이터를 손실 없이 보관할 방법이 필요
- 큰 데이터 저장이 가능한 분산 파일 시스템이 필요
- 병렬 처리
- 처리 시간이 오래 걸림
- 병렬 처리가 가능한 분산 컴퓨팅 시스템이 필요
- SQL만으로는 부족
- 비구조화된 데이터일 가능성이 높음, 예) 웹 로그
- 비구조화 데이터를 처리할 방법이 필요
- 결론적으로 다수의 컴퓨터로 구성된 프레임워크가 필요
대용량 분산 시스템
- 분산 환경 기반 (1대 이상의 서버) : 분산 파일 시스템과 분산 컴퓨팅 시스템이 필요
- Fault Tolerance : 소수의 서버가 고장 나도 동작해야 함
- 확장 용이 : Scale Out이 돼야 함

하둡의 등장과 소개
하둡(Hadoop)의 등장
- Doug Cutting이 구글랩 발표 논문에 기반해 만든 오픈소스 프로젝트
- 2003년 The Google File System
- 2004년 MapReduce: Simplified Data Processing on Large Cluster
- 처음 시작은 Nutch라는 오픈소스 검색엔진 하부 프로젝트
하둡(Hadoop)이란?
- 다수의 노드로 구성된 클러스터 시스템
- 마치 하나의 거대한 컴퓨터처럼 동작
- 사실은 다수의 컴퓨터가 복잡한 소프트웨어로 통제됨
- 초기) 분산 파일 시스템 : HDFS, 분산 컴퓨팅 시스템 : MapReduce
하둡(Hadoop)의 발전
- 하둡 1.0
- HDFS 위에 MapReduce라는 분산 컴퓨팅 시스템이 실행되는 구조
- MapReduce 위에서 다양한 컴퓨팅 언어가 만들어짐 (Presto, Hive)

- 하둡 2.0
- 1.0과 비교해 아키텍처가 크게 변경
- 하둡은 YARN이란 이름의 분산처리 시스템 위에서 동작하는 애플리케이션이 됨
- Spark는 YARN 위에서 애플리케이션 레이어로 실행

- 하둡 3.0
- YARN 2.0 사용
- Application 용도에 따라 YARN의 자원 관리 가능
- 타임라인 서버에서 HBase를 기본 스토리지로 사용 (하둡 2.1)
- 파일 시스템
- 다수의 Standby 네임노드 지원
- HDFS, S3, Azure Storage 이외에 Azure Data Lake Storage 등을 지원
- YARN 2.0 사용
HDFS : 분산 파일 시스템
- 데이터를 블록 단위로 나눠 저장
- 블록의 크기는 128 MB (default)
- 블록 복제 방식 (Replication)
- 각 블록은 세 곳에 중복 저장
- Fault Tolerance를 보장할 수 있는 방식으로 블록 저장
- 하둡 2.0 네임 노드 이중화 지원
- Active 네임 노드 & Standby 네임 노드, 둘 사이에 share edit log가 존재
- Active 네임 노드에 문제가 생기면 Standby 네임 노드가 대체하여 작동
- 네임 노드에 문제가 생겼을 경우를 대비한 Secondary 네임 노드는 여전히 존재

MapReduce : 분산 컴퓨팅 시스템 (하둡 1.0)
- 하둡 1.0
- 하나의 잡 트레커와 다수의 태스크
- 잡 트레커가 일을 나눠 다수의 태스크 트래커에게 분배
- 태스크 트래커에서 병렬 처리
- MapReduce만 지원하며, 제너럴한 시스템이 아님

YARN의 동작 방식
분산 컴퓨팅 시스템 : 하둡 2.0 (YARN 1.0)
- 세부 리소스 관리가 가능한 범용 컴퓨팅 프레임워크
- 리소스 매니저 : Job Scheduler, Application Manager
- 노드 매니저
- 컨테이너 : 맵 마스터, 태스크
- Spark가 YARN 위에서 구현
- 여기서의 client는 MapReduce, Spark 등

YARN의 동작
- 실행 코드와 환경 정보를 Resource Manager에게 제출
- 실행에 필요한 파일은 Application ID에 해당하는 HDFS 폴더에 미리 복사됨
- Resource Manager는 Node Manager을 통해 Application Master 실행
- Application Master는 프로그램마다 하나씩 할당되는 프로그램 마스터에 해당
- Application Master가 Resource Manger로 코드 실행에 필요한 리소스를 받아옴
- Resource Manager는 Data Locality를 고려해서 리소스 (컨테이너)를 할당
- Application Master에 Node Manager을 통해 컨테이너를 받아 코드 실행 (Task)
- 실행에 필요한 파일이 HDFS에 컨테이너가 있는 서버로 먼저 복사
- 태스크는 자신의 상황을 주기적으로 Application Master에게 업데이트 (Heartbeat)
- 태스크가 실패하거나 보고가 오랜 시간 없으면 태스크를 다른 컨테이너에서 재실행

맵리듀스 프로그래밍 소개
맵리듀스 프로그래밍의 특징
- 기본적으로 큰 데이터를 처리할 수 있는 것에 목표를 둠
- 데이터 셋은 Key, Value의 집합이며 변경 불가
- 데이터 조작은 map과 reduce 두 개의 오퍼레이션으로만 가능
- 두 오퍼레이션은 항상 하나의 쌍으로 연속으로 실행
- 오퍼레이션의 코드는 개발자가 채워야 함
- 맵리듀스 시스템이 map의 결과를 reduce 단으로 모아줌
- 이 단계를 보통 셔플링이라 부르며 네트워크 단을 통한 데이터 이동이 생김
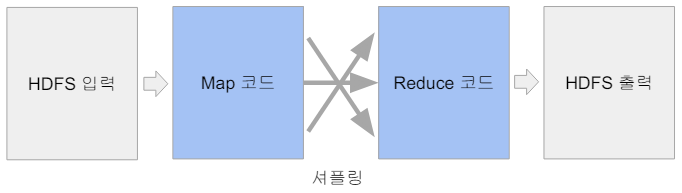
Map과 Reduce
- Map : (k, v) -> [(k', v')*]
- 입력은 시스템에 의해 주어지며, 입력으로 지정된 HDFS 파일에서 넘어옴
- 코드를 통해 key, value 페어를 새로운 key, value 페어 리스트로 변환 (transformation)
- 출력 : 입력과 동일한 key, value 페어를 그대로 출력해도 되고 출력이 없어도 됨
- Reduce : (k', [v1', v2', v3', v4', ...]) -> (k'', v'')
- 입력은 시스템에 의해 주어짐
- key와 value 리스트를 새로운 key, value 페어로 변환
- SQL의 GROUP BY와 흡사
- 출력이 HDFS에 저장됨
맵리듀스 프로그램 동작 예시 : Word Count

Shuffling & Sorting
- Shuffling
- Mapper의 출력을 Reducer로 보내주는 프로세스
- 전송되는 데이터의 크기가 크면 네트워크 병목을 초래하고 시간이 오래 걸림
- Sorting
- 모든 Mapper의 출력을 Reducer가 받으면 이를 키 별로 정렬

Data Skew
- 각 태스크가 처리하는 데이터 크기에 불균형이 존재한다면?
- 병렬처리의 큰 의미가 없음, 가장 느린 태스크가 전체 처리 속도를 결정
- Reducer의 입력 데이터의 크기는 큰 차이가 있을 수 있음
- 빅데이터 시스템에는 이 문제가 모두 존재
맵리듀스 프로그래밍의 문제점
- 낮은 생산성
- 프로그래밍 모델이 가진 융통성 부족 : 2가지 오퍼레이션만 지원
- 튜닝 / 최적화가 쉽지 않음, 예) Data Skew
- 배치작업 중심
- 기본적으로 Low Latency가 아닌 Throughput에 초점을 맞춤
맵리듀스 대안의 등장
- 범용적인 대용량 처리 프레임워크 등장 : YARN, Spark 등
- SQL의 컴백
- Hive : MapReduce 위에 구현, Throughput에 초점, 대용량 ETL에 적합
- Presto : Low Latency에 초점, 메모리를 주로 사용하며 Adhoc 쿼리에 적합
Spark 소개
Spark의 등장
- 버클리 대학의 AMPLab에서 아파치 오픈소스 프로젝트로 2013년에 시작
- 하둡의 뒤를 잇는 2세대 빅데이터 기술
- YARN 등을 분산환경으로 사용
- Scala로 작성
- 빅데이터 처리 관련 다양한 기능을 제공
Spark 3.0의 구성
- Spark Core
- Spark SQL
- Spark ML / Spark MLlib
- Spark Streaming
- Spark Graph
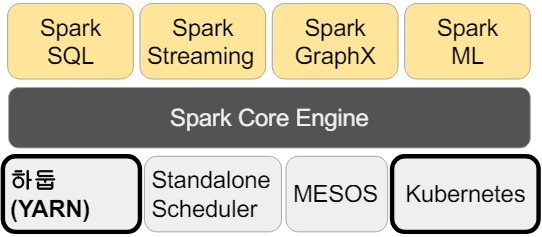
Spark vs MapReduce
- 메모리 or 디스크
- Spark : 기본적으로 메모리 기반이고, 메모리가 부족해지면 디스크 사용
- MapReduce : 디스크 기반
- 분산 컴퓨팅 환경
- Spark : 다른 분산 컴퓨팅 환경 지원 (k8s 등)
- MapReduce : 하둡 (YARN) 위에서만 동작
- 데이터 구조
- Spark : pandas dataframe과 개념적으로 동일한 데이터 구조 지원
- MapReduce : key, value 기반 데이터 구조만 지원
- 컴퓨팅 방식
- Spark : 배치 데이터 처리, 스트림 데이터 처리, SQL, 머신러닝 등 다양한 방식의 컴퓨팅 지원
- MapReduce : 배치 데이터 처리만 지원
Spark 프로그래밍 API
- RDD (Resilient Distributed Dataset)
- 로우 레벨 프로그래밍 API로 세밀한 제어가 가능
- 코딩 복잡도 증가
- DataFrame & Dataset (pandas의 dataframe과 흡사)
- 하이 레벨 프로그래밍 API로 점점 많이 사용되는 추세
- 구조화 데이터 조작이라면 보통 Spark SQL을 사용
Spark SQL
- Spark SQL은 구조화된 데이터 처리를 SQL로 처리
- 데이터 프레임을 SQL로 처리 가능 (판다스도 동일 기능 제공)
- Hive 쿼리보다 최대 100배까지 빠른 성능을 보장
- 그러나 Hive도 그 사이 메모리를 쓰는 방향으로 발전
- Hive : 디스크 -> 메모리, Spark : 메모리 -> 디스크, Presto : 메모리 -> 디스크
Spark ML
- 머신러닝 관련 다양한 알고리즘, 유틸리티로 구성된 라이브러리
- 지원하는 알고리즘 : Classification, Regression, Clustering, Collaborative Filtering 등
- 딥러닝은 거의 지원하지 않음
- RDD 기반과 데이터프레임 기반 두 버전이 존재 : spark.mllib vs spark.ml
- MLlib는 RDD 기반, ML은 데이터프레임 기반
- MLilb는 더 이상 업데이트가 진행되지 않아 ML을 사용해야 함
- 장점
- 데이터 프레임과 Spark SQL 등을 이용해 전처리
- Spark ML로 모델 빌딩
- ML Pipeline을 통해 모델 빌딩 자동화
- MLflow로 모델 관리와 서빙 (MLOps)
- 대용량 데이터 처리도 가능
Spark 데이터 시스템 사용 예
- 대용량 배치 처리, 스트림 처리, 모델 빌딩
- 대용량 비구조화된 데이터 처리 (ETL or ELT)
- ML 모델에 사용되는 대용량 피쳐 정리 (배치 / 스트림)
- Spark ML을 이용한 대용량 훈련 데이터 모델 학습
Spark 프로그램 실행 옵션
Spark가 YARN 위에서 실행 중이라고 할 때 필요한 실행 옵션에 대해 알아본다.
Spark 프로그램 실행 환경
- 개발 / 테스트 / 학습 환경 (Interactive Clients)
- 노트북 (주피터, 제플린)
- Spark Shell
- 프로덕션 환경 (Submit Job)
- spark-submit (command-line utility) : 가장 많이 사용
- 데이터브릭스 노트북 : 코드를 주기적으로 실행하는 것이 가능
- REST API : Spark Standalone 모드에서만 가능, API로 Spark Job 실행
Spark 프로그램의 구조
- Driver
- 실행되는 코드의 마스터 역할 수행 (YARN의 Application Master)
- 사용자 코드를 실행하며, 실행 모드(client, cluster)에 따라 실행되는 곳이 달라짐
- 코드를 사용할 때 필요한 리소스 지정
- --num-executors : executor 개수
- --executor-cores : CPU 수
- --executor-memory : 메모리 크기
- SparkContext를 만들어 Spark 클러스터와 통신 수행
- Cluster Manager : YARN의 Resource Manager
- Executor : YARN의 Container
- 사용자 코드를 실제 Spark 태스크로 변환해 Spark 클러스터에서 실행
- Executor
- 실제 태스크를 실행해 주는 역할 수행 (YARN의 컨테이너)
- 실제 태스크를 실행해 주는 역할 수행 (JVM) : Transformations, Actions
- YARN의 Container

Spark Cluster Manager 옵션
- local [n]
- 개발 / 테스트용 : Spark Shell, IDE, 노트북 사용
- n은 코어의 수 = Executor의 수
- local [*] : 컴퓨터에 존재하는 모든 코어 사용
- YARN
- client 모드 : Driver가 YARN 클러스터 외부에서 동작, 개발 / 테스트 등을 할 때 사용
- cluster 모드 : Driver가 YARN 클러스터 내에서 동작, 실제 프로덕션 운영에 사용되는 모드

- Kubernetes
- Mesos
- Standalone
Reference
'[프로그래머스] 데이터 엔지니어링 데브코스 3기 > TIL(Today I Learn)' 카테고리의 다른 글
| [TIL - 63일 차] 하둡과 Spark (3) (0) | 2024.06.19 |
|---|---|
| [TIL - 62일 차] 하둡과 Spark (2) (0) | 2024.06.18 |
| [TIL - 55일 차] Airflow 고급기능과 DBT, 데이터 디스커버리 (5-2) (0) | 2024.06.07 |
| [TIL - 55일 차] Airflow 고급기능과 DBT, 데이터 디스커버리 (5-1) (2) | 2024.06.07 |
| [TIL - 54일 차] Airflow 고급기능과 DBT, 데이터 디스커버리 (4) (2) | 2024.06.06 |