
머신러닝 기초
머신러닝 (기계 학습)
Machine Learning
- 경험을 통해 자동으로 개선하는 컴퓨터 알고리즘 연구
- 학습 데이터
- 입력 벡터 : x1, x2, ..., xn
- 목표 값 : t1, t2, ..., tn
- 머신러닝 알고리즘의 결과는 목표 값을 예측하는 함수 y(x)
- y(x1) ~ t1, y(x2) ~ t2, ..., y(x3) ~ t3
예제 : 숫자 인식 (MNIST)
- 입력 벡터 : 이미지 Color Matrix (아래 이미지 예시 참고)
- 목표 값 : 이미지가 나타내는 수


핵심 개념
- 학습 단계 (Training, Learning Phase) : 함수 y(x)를 학습 데이터에 기반해 결정하는 단계
- 테스트 데이터셋 : 모델을 평가하기 위해 사용하는 별도의 데이터
- 일반화 (Generalization) : 모델이 새로운 데이터에 대해 올바른 예측을 수행하는 역량
- 지도 학습 (Supervised Learning) : 목표 값(Target, Label)이 주어진 경우
- 분류 (Classification) : 목표 값이 이산적인 경우
- 회귀 (Regression) : 목표 값이 연속적인 경우
- 비지도 학습 (Unsupervised Learning) : 목표 값(Target, Label)이 없는 경우
- 군집 (Clustering) : 비슷한 특성을 갖고 있는 데이터끼리 그루핑
머신러닝 기초 개념
다항식 곡선 근사 (Polynomial Curve Fitting)
- Sin 함수가 데이터를 생성
- 학습 시 데이터 생성 방법은 모른다고 가정
- 목표 : 새로운 입력 벡터 x가 주어졌을 때 목표 값 t를 예측하는 것


머신러닝에 확률이 필요한 이유
- 확률 이론(Probability Theory) : 예측 값의 불확실성을 정량화시켜 표현 가능한 수학적인 프레임워크 제공
- 결정 이론(Decision Theory) : 확률적 표현을 바탕으로 최적의 예측을 수행할 수 있는 방법론 제공
오차 함수 (Error Function)
- E(w)를 최소화시키는 w를 구하는 것이 목표
- 실제 데이터 : t (파란 점)
- 예측 데이터 : y(x, w) (빨간 선)


과소 적합 (Under-fitting)과 과대 적합 (Over-fitting)
- 과소 적합 : 모델이 단순해서 데이터를 충분히 표현하지 못함
- 과대 적합 : 모델이 복잡해서 새로운 데이터를 예측하지 못함
- M = 0, M = 1 : 과소 적합
- M = 9 : 과대 적합
- M = 3 : 가장 적합한 모델

- 데이터의 차원이 높아지면 시각적으로 과소 적합과 과대 적합을 확인할 수 없음
- 이는 일반화의 문제이므로 학습 데이터와 테스트 데이터의 오차를 구해보면 확인 가능
- M= 9일 경우 학습 데이터의 오차는 0이지만 테스트 데이터의 오차는 증가 -> 과대 적합
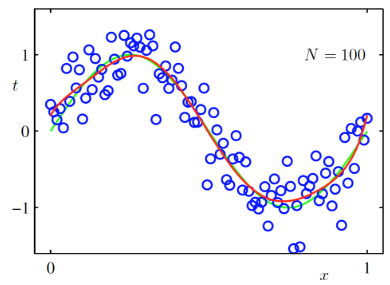
- 데이터의 개수가 증가할수록 복잡한 모델을 구성할 수 있음
- 데이터의 개수를 늘리고 M = 9인 모델을 만들면 Sin 그래프에 근접

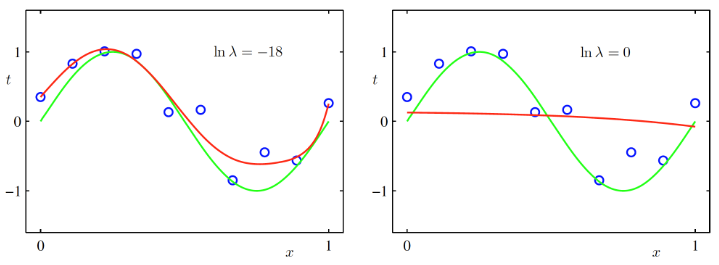
규제화 (Regularization)
- 오차 함수에 새로운 항을 도입하여 모델의 안정성을 증대

'[프로그래머스] 데이터 엔지니어링 데브코스 3기 > TIL(Today I Learn)' 카테고리의 다른 글
| [TIL - 73일 차] 음식 배달에 걸리는 시간 예측하기 (2) (0) | 2024.07.03 |
|---|---|
| [TIL - 72일 차] 음식 배달에 걸리는 시간 예측하기 (1) (0) | 2024.07.02 |
| [TIL - 70일 차] Kafka와 Spark Streaming 기반 스트리밍 처리 (5) (0) | 2024.06.28 |
| [TIL - 69일 차] Kafka와 Spark Streaming 기반 스트리밍 처리 (4) (0) | 2024.06.28 |
| [TIL - 68일 차] Kafka와 Spark Streaming 기반 스트리밍 처리 (3) (0) | 2024.06.26 |