
[TIL - 72일 차] 음식 배달에 걸리는 시간 예측하기 (1)
오늘 강의는 "선형대수 기초"이지만, 이미 대학교에서 강의를 수강하기도 했고 수식이 많아 모두 정리하기에 무리가 있어 학습은 영상으로만 진행하였다. 대신에 머신러닝 과제인 "음식 배달에
sanseo.tistory.com
이전에 문제 이해와 데이터 전처리, 하이퍼 파라미터 튜닝 코드까지 작성해 보았다. 그러나 학습 시간이 생각보다 오래 걸려 KFold를 사용하지 않은 방법으로 사용해보려고 한다. 또한 테스트 데이터의 예측과 under_prediction의 비율도 확인해 보자.
음식 배달에 걸리는 시간 예측하기
진행 과정
하이퍼 파라미터 튜닝
- KFold (교차 검증) 부분을 삭제하고 train_test_split 사용
- 실행 결과
- 최소 rmse : 729.44
- 하이퍼 파라미터 : {'n_estimators': 261, 'max_depth': 36, 'min_samples_split': 20, 'min_samples_leaf': 1}
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import accuracy_score
from sklearn.metrics import mean_squared_error
import numpy as np
import optuna
X = train.drop(['label'], axis=1)
y = train['label']
# Objective function 정의
def objective(trial):
# 하이퍼파라미터 설정
n_estimators = trial.suggest_int('n_estimators', 50, 300)
max_depth = trial.suggest_int('max_depth', 5, 40)
min_samples_split = trial.suggest_int('min_samples_split', 2, 30)
min_samples_leaf = trial.suggest_int('min_samples_leaf', 1, 30)
# 랜덤 포레스트 회귀 모델 생성
model = RandomForestRegressor(
n_estimators=n_estimators,
max_depth=max_depth,
min_samples_split=min_samples_split,
min_samples_leaf=min_samples_leaf,
random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
model.fit(X, y)
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f'rmse : {rmse}')
return rmse
# Callback 함수 정의
def print_callback(study, trial):
print(f'Trial {trial.number}: RMSE={trial.value:.2f}, Params={trial.params}')
# Optuna 스터디 생성 및 최적화 실행
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=10, callbacks=[print_callback])
# 최적의 하이퍼파라미터 출력
print(f'Best hyperparameters: {study.best_params}')
print(f'Best RMSE: {study.best_value:.2f}')모델 생성 및 학습 데이터 예측
- optuna를 통해 얻은 최적의 하이퍼 파라미터 값을 대입
- 실행 결과
- rmse : 731.22
X = train.drop(['label'], axis=1)
y = train['label']
model = RandomForestRegressor(
n_estimators=149,
max_depth=18,
min_samples_split=20,
min_samples_leaf=20,
random_state=42
)
model.fit(X, y)
y_pred = model.predict(X)
rmse = np.sqrt(mean_squared_error(y, y_pred))
print(f'RMSE : {rmse}')- under_prediction rate 계산 : 실제 배달 시간보다 예측 시간이 적은 경우
- 실행 결과
- under_prediction rate : 0.412
under_prediction = pd.DataFrame(train[['label']])
under_prediction['pred'] = y_pred
round((under_prediction['label'] >= under_prediction['pred']).sum()/len(under_prediction), 3)테스트 데이터 예측
- 실행 결과
- rmse : 979.74
- under_prediction : 0.409
X_test = test.drop(['label'], axis=1)
y_test = test['label']
y_pred_test = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, y_pred_test))
print(f'RMSE : {rmse}')under_prediction_test = pd.DataFrame(test[['label']])
under_prediction_test['pred'] = y_pred_test
round((under_prediction_test['label'] >= under_prediction_test['pred']).sum()/len(under_prediction_test), 3)테스트 실제값과 예측값 비교
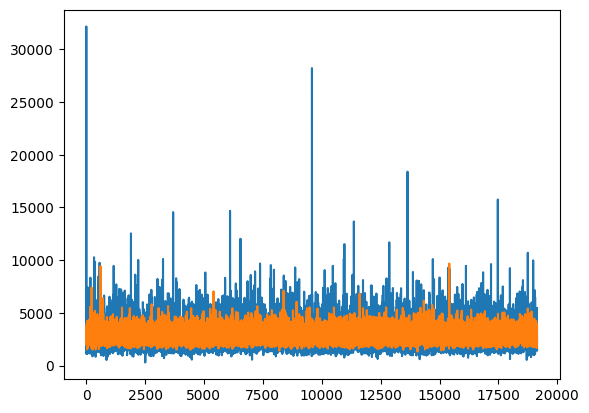
- 파란색 : 실제 배달 시간
- 주황색 : 예측 배달 시간
- 대체로 실제 배달 시간이 길면, 더 짧은 배달 시간으로 예측
- 반대로 실제 배달 시간이 짧으면, 더 긴 배달 시간으로 예측
'[프로그래머스] 데이터 엔지니어링 데브코스 3기 > TIL(Today I Learn)' 카테고리의 다른 글
| [TIL - 77일 차] Spark, SparkML 실습 (2) (0) | 2024.07.09 |
|---|---|
| [TIL - 76일 차] Spark, SparkML 실습 (1) (0) | 2024.07.08 |
| [TIL - 72일 차] 음식 배달에 걸리는 시간 예측하기 (1) (0) | 2024.07.02 |
| [TIL - 71일 차] 머신러닝 기초 (0) | 2024.07.01 |
| [TIL - 70일 차] Kafka와 Spark Streaming 기반 스트리밍 처리 (5) (0) | 2024.06.28 |