
이전에 위비티 사이트를 스크래핑하고 데이터를 저장하는 작업을 진행하였다. 마지막으로 씽굿을 스크래핑하고 저장하는 작업을 진행할 것이다.
[개인 프로젝트] 공모전 크롤링 (5) - 데이터 수집 (스크래핑) - 위비티
이전에 모델의 url을 URLField로 수정하고, 링커리어의 데이터를 스크래핑하고 저장하는 작업을 하였다. 이번에는 다른 공모전 사이트인 위비티의 데이터를 스크래핑하고 저장하는 작업을 진행한
sanseo.tistory.com
변경 사항
씽굿을 추가하면서 if-elif 구문에 추가해 주었다. 또한 한글 형태가 아닌 영어로 변경하였다. 이에 따라 scraping_linkcarrer.py, scraping_wevity.py에서 함수를 호출할 때의 platform 인자가 영어로 변경되었다.
save.py
import os
import django
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'moremore.settings')
django.setup()
from datetime import datetime
from mainpage.models import Competition
def save_data_to_database(platform, title, url, application_start, application_end):
if platform == 'linkcarrer':
for t, u, start, end in zip(title, url, application_start, application_end):
Competition.objects.create(
platform=platform,
title=t,
url=u,
application_start=datetime.strptime(start, "%y.%m.%d").strftime("%Y-%m-%d"),
application_end=datetime.strptime(end,"%y.%m.%d").strftime("%Y-%m-%d")
)
elif platform in ['wevity', 'thinkgood']:
for t, u, start, end in zip(title, url, application_start, application_end):
Competition.objects.create(
platform=platform,
title=t,
url=u,
application_start=datetime.strptime(start,'%Y-%m-%d'),
application_end=datetime.strptime(end,'%Y-%m-%d')
)scraping_linkcarrer.py
if __name__ == "__main__":
title, url, application_start, application_end = scraping_linkcarrer()
save_data_to_database('linkcarrer', title, url, application_start, application_end)scraping_wevity.py
if __name__ == "__main__":
title, url, application_start, application_end = scraping_wevity()
save_data_to_database('wevity', title, url, application_start, application_end)데이터 수집 - 씽굿
씽굿-대한민국 대표 공모전 미디어 씽굿
www.thinkcontest.com
씽굿 링크 및 목록 형태
링크
링크는 아래와 같다. 링크 주소가 너무 길어 중간까지만 가져왔다. 이전 사이트와 같이 "page={i}" 형태로 되어있지 않기 때문에 여기서는 selenium 라이브러리를 사용해서 클릭을 통해 다음 페이지로 넘어갈 수 있도록 진행할 것이다.

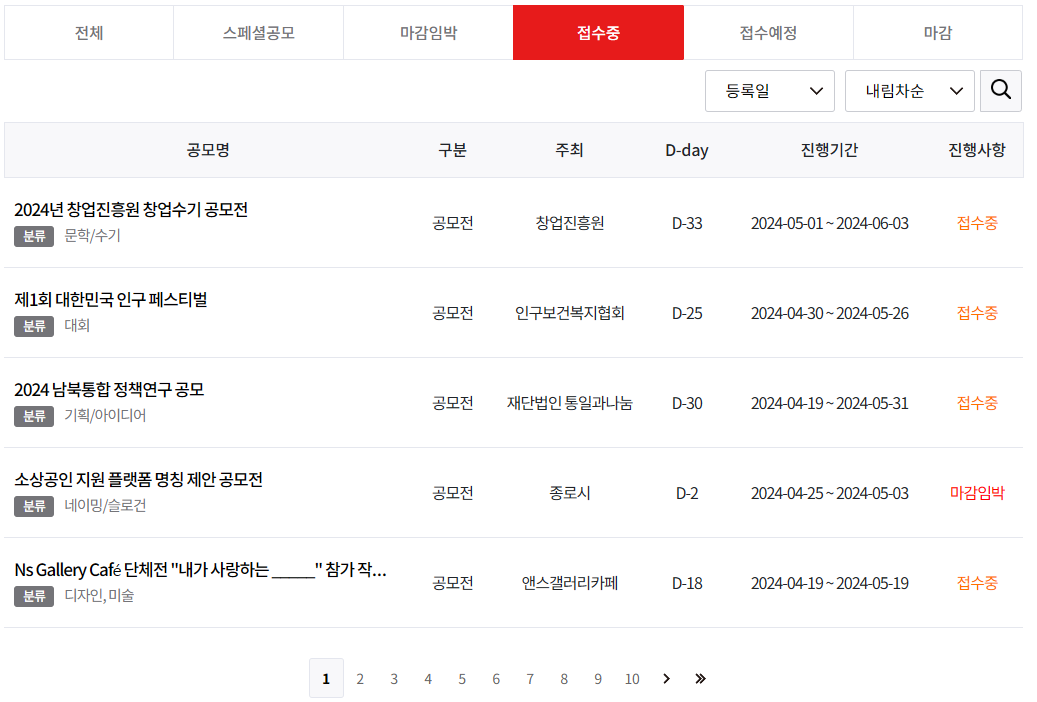
페이지
페이지의 일부를 캡쳐한 것이다. 씽굿은 진행 기간을 메인 페이지에서 볼 수 있기 때문에 필요한 정보를 얻는 데 시간이 훨씬 빠를 것이라 생각한다. 또한 공모명이 길어 ...으로 생략되는 부분이 있는데, 관리자 도구로 확인해 보면 풀네임을 확인할 수 있기 때문에 큰 문제없이 진행할 수 있을 것이다.
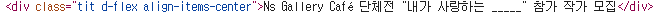
URL 스크래핑
지금까지와 달리 해당 공모전의 링크가 <a> 태그로 감싸져있는 형태가 아니었다. 자세히는 모르겠지만, pk 값이 있기도 했다. 그러나 공모전 링크 또한 id 값이 쓰이는 것이 아닌 위와 같은 이상한 문자열이 나열돼 있었다. 그래서 URL은 해당 공모전을 클릭하여 접속 후에 주소값을 가져오는 형태로 작성해야 할 것이다.
반복문 종료 기준
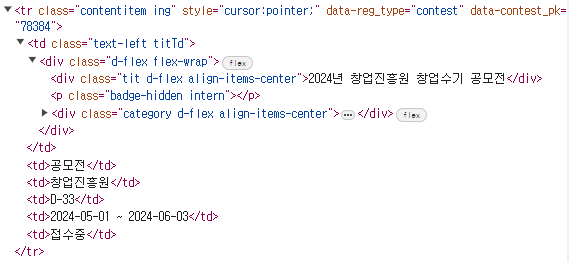
씽굿의 마지막 페이지 기준은 next-arrow가 존재하지 않을 경우로 설정하였다. 위의 Content 이미지를 보면, 다음 페이지가 존재하면 '>'처럼 다음 페이지 링크가 존재한다. 이 링크가 존재하지 않을 경우 마지막 페이지로 간주하였다.
코드
try-except 구문에서 다음 페이지를 찾기 위해 CSS_SELECTER를 사용하였다.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from save import save_data_to_database
def scraping_thinkgood():
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
page_number = 1
title, url, application_start, application_end = [], [], [], []
while True:
if page_number == 1:
driver.implicitly_wait(10)
driver.get("https://www.thinkcontest.com/thinkgood/user/contest/index.do#PxyyoRLHIcgvNg6HiHNz_uA4QOthhmxuMkOJ-8OGsYHuum-XS7oXTXHj_WQpSdho7EnVynWoiuBwl84H1ChINGL0PwCVS2cspmoqCGi-qpZY6T5M_ZxBwx9fWgmwB-cK")
titles = driver.find_elements(By.CLASS_NAME, "tit")
contents = driver.find_elements(By.CLASS_NAME, "contentitem")
print(f"{page_number} 페이지 스크래핑 시작")
for t in titles:
if t.tag_name == 'div':
title.append(t.text)
for c in contents:
driver.implicitly_wait(3)
c.click()
url.append(driver.current_url)
driver.back()
for c in contents:
date = c.find_elements(By.TAG_NAME, 'td')[4].text
application_start.append(date.split(' ')[0])
application_end.append(date.split(' ')[2])
print(f"{page_number} 페이지 스크래핑 완료")
try:
driver.implicitly_wait(3)
arrow_next_element = driver.find_element(By.CSS_SELECTOR, '#pagination1 > a.next')
arrow_next_element.click()
except NoSuchElementException:
print(f"모든 페이지 스크래핑 완료")
break
page_number += 1
driver.quit()
return title, url, application_start, application_end
if __name__ == "__main__":
title, url, application_start, application_end = scraping_thinkgood()
save_data_to_database('thinkgood', title, url, application_start, application_end)git push
git add .
git commit -m "feat, fix: add scraping thinkgood, change platform parameter korean to english"
git push origin main데이터 수집까지 모두 완료되었으므로 이제 프론트 작업을 진행한다. 다음에는 메인페이지의 코드를 작성할 것이다.
[개인 프로젝트] 공모전 크롤링 (7) - 메인 페이지 (프론트)
이전에 씽굿을 스크래핑하고 저장하는 작업을 진행하였다. 데이터 수집까지 모두 완료되었으므로 이제 프론트 작업을 진행한다. 이번에는 메인페이지의 코드를 작성할 것이다. [개인 프로젝트
sanseo.tistory.com
'프로젝트 단위 공부 > [개인 프로젝트] 공모전 크롤링' 카테고리의 다른 글
| [개인 프로젝트] 공모전 크롤링 (8) - 메인 페이지(공모전 표시), 데이터 csv 저장 (2) | 2024.05.03 |
|---|---|
| [개인 프로젝트] 공모전 크롤링 (7) - 메인 페이지 (프론트) (2) | 2024.05.02 |
| [개인 프로젝트] 공모전 크롤링 (5) - 데이터 수집 (스크래핑) - 위비티 (2) | 2024.05.01 |
| [개인 프로젝트] 공모전 크롤링 (4) - 데이터 수집 (스크래핑) - 링커리어 (0) | 2024.04.29 |
| [개인 프로젝트] 공모전 크롤링 (3) - mainpage (App 연동, Model 생성) (0) | 2024.04.27 |