
과제 안내
과제는 시각화 도구를 사용해 선택한 데이터셋에 대한 특정한 질문들을 만들고 대답하는 것이다. 모든 질문의 시작부터 끝까지 과제 수행 과정이 문서화되어야 한다. 이 과제의 목표는 탐색적인 데이터 분석을 수행하기 위해 시각화를 사용하는 과정을 더 잘 이해하는 것이다.
1) 관심 있는 데이터셋 선정
가장 관심 있는 분야의 데이터셋을 고른다.
2) 대답하고 싶은 초기 질문 선정
예를 들어, 녹는점과 원자 번호 사이에 관계가 있나요?, 별의 밝은 정도와 색깔이 서로 연관이 있나요? 등
3) 질문에 답하기 위한 데이터 적합성 평가
데이터의 원시 값을 먼저 보는 것은 도움이 되며, 데이터가 질문에 답하기에 적합한지 확인한다. 적합하지 않다면, 위의 과정을 다시 시작하는 것이 좋다. 시각적으로 분석하기 전에 원하는 모습으로 데이터를 얻기 위해 필요한 모든 단계를 진행한다.
최종 보고서에 포함돼야 할 것
- 스토리보드 : 이 데이터셋을 왜 선택했고 무엇을 이루려는 것인지를 포함한다.
- 시각화 : 최소한 4가지 타입의 시각화와 더불어 차원이 축소된 시각화가 있어야 한다.
- 소스코드 : 제출된 코드가 순서대로 잘 동작하는지 확인하고, 실행할 때 특별한 안내가 필요하면 보고서에 포함시킨다.
데이터셋 선정
3대 운동 무게 측정과 관련된 kaggle의 데이터 "powerlifting-database"를 분석하기로 결정하였다. 3대 운동이 몸무게, 나이, 장비 착용에 따라 어떻게 변화하는지 알아보고자 한다.
Column
- MeetID : (?)
- Name : 이름
- Sex : 성별
- Equipment : 장비 착용
- Age : 나이
- Division : (?)
- BodyweightKg : 몸무게
- WeightClassKg : 몸무게 분류
- Squat4Kg : 스쿼트 4번 째 시도
- BestSquatKg : 최대 스쿼트 무게
- Bench4Kg : 벤치프레스 4번째 시도
- BestBenchKg : 최대 벤치프레스 무게
- Deadlift4Kg : 데드리프트 4번째 시도
- BestDeadliftKg : 최대 데드리프트 무게
- TotalKg : 총 3대 운동 무게
- Place : (?)
- Wilks : Best Lifter 공식으로 사용되는 점수
초기 질문 선정
4개 질문 모두 유사한 방식으로 해결될 것 같기 때문에 선정한 질문 중 첫 질문만 답해보려 한다.
- 몸무게가 많이 나가면 3대 운동 무게도 높을까?
- 장비를 착용하면 3대 운동 무게가 증가할까?
- 3대 운동 중 몸무게와 가장 관련이 높은 것은 무엇일까?
- 나이에 따른 3대 운동 무게는 어떻게 변화할까?
몸무게가 많이 나가면 3대 운동 무게도 높을까?
필요한 열만 남긴 데이터를 가지고 상관계수, 선형 회귀 분석을 진행한다. 이후 분석 결과를 토대로 몸무게와 3대 운동이 어떤 연관이 있는지 알아보고자 한다.
질문에 답하기 위한 데이터 전처리
몸무게와 3대 운동을 비교할 것이기 때문에 'BodyweightKg', 'BestSquatKg', 'BestBenchKg', 'BestDeadliftKg' 열을 추출하여 새로운 데이터를 생성한다. 또한 일반적인 경우를 알아보기 위해 몸무게를 60 ~ 100 kg으로 제한하여 분석을 진행한다. 결과적으로 386414개의 데이터 행의 개수가 243728로 줄었지만, 충분한 데이터의 수를 가지고 있다고 판단된다.
data_1 = df[['BodyweightKg', 'BestSquatKg', 'BestBenchKg', 'BestDeadliftKg']]
data_1 = data_1[data_1['BodyweightKg'] >= 60]
data_1 = data_1[data_1['BodyweightKg'] <= 100]이상치 및 결측치 제거
결측치 확인 결과 'BestSquatKg'가 51798개로 가장 많았다. 약 24만 개의 데이터에서 5 ~ 6만 개의 데이터를 제외한 18만 개의 데이터로도 충분히 분석이 가능하다고 판단하여 결측치를 가진 모든 행을 제거하고 분석을 진행한다. 결과적으로 185428개의 데이터 행이 남았다.
data_1.isnull().sum()
# BodyweightKg 0
# BestSquatKg 51798
# BestBenchKg 17375
# BestDeadliftKg 39944
data_1 = data_1.dropna()
data_1.isnull().sum()
# BodyweightKg 0
# BestSquatKg 0
# BestBenchKg 0
# BestDeadliftKg 0이상치 확인 결과 'BestSquatKg', 'BestBenchKg', 'BestDeadliftKg' 열에서 음수 값이 존재하였다. 따라서 양수의 열만 추출하였다.
print((data_1['BestSquatKg'] < 0).sum())
print((data_1['BestBenchKg'] < 0).sum())
print((data_1['BestDeadliftKg'] < 0).sum())
print((data_1['BodyweightKg'] < 0).sum())
# 316
# 314
# 217
# 0
data_1 = data_1[data_1['BestSquatKg'] >= 0]
data_1 = data_1[data_1['BestBenchKg'] >= 0]
data_1 = data_1[data_1['BestDeadliftKg'] >= 0]피어슨 상관계수 분석
상관계수를 알아볼 수 있는 방법들 중에서 선형 관계를 확인할 수 있는 피어슨 상관계수 분석 방법을 사용하였다. 상관계수에서는 몸무게와 3대 운동은 큰 관계가 존재하지는 않는다는 것을 알 수 있었다. 그러나 3대 운동 서로의 관계가 존재하는 것을 알 수 있었다. 이는 스쿼트의 무게가 높으면 벤치프레스나 데드리프트의 무게도 높다는 것을 의미한다.
corr = data_1.corr(method='pearson')
sns.heatmap(corr, annot=True, cmap='Blues')
선형 회귀 분석
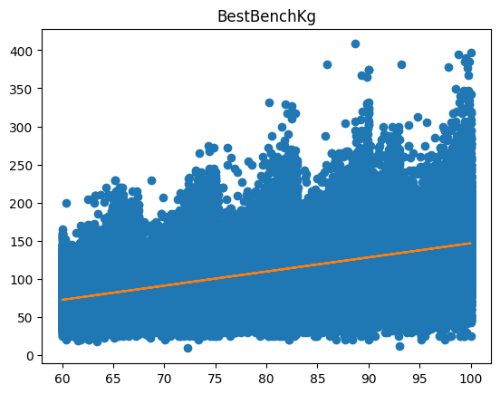
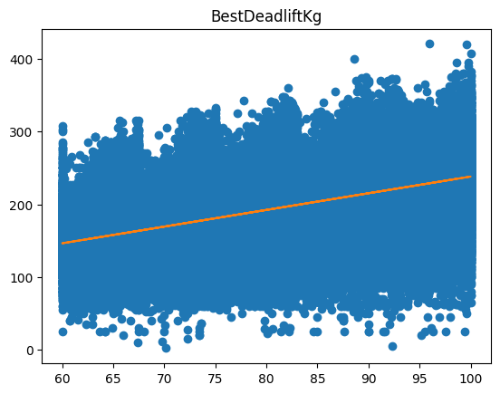
단일 회귀 분석 방법을 3번 사용하여 각 운동과 몸무게의 선형 관계를 알아보았다. 확인 결과 몸무게가 증가할수록 스쿼트, 벤치프레스, 데드리프트의 무게가 대체로 증가하는 모습을 확인할 수 있었다. 또한 상관분석에서 확인할 수 있었던 3대 운동 간의 연관성을 각 데이터의 분포를 통해 알 수 있었다.(비슷한 분포 형태를 가지고 있다.)
X = data_1['BodyweightKg']
y = data_1['BestSquatKg']
lr1 = LinearRegression()
lr1.fit(X.values.reshape(-1, 1), y)
plt.plot(X, y, 'o')
plt.plot(X, lr1.predict(X.values.reshape(-1,1)))
plt.show()

참고 링크
DataLit : 데이터 다루기
https://www.boostcourse.org/ds103/joinLectures/84465
kaggle data : powerlifting-database
https://www.kaggle.com/datasets/dansbecker/powerlifting-database
선형회귀(Linear Regression) – 파이썬 코드 예제
https://hleecaster.com/ml-linear-regression-example/
전체 코드 - Colab
https://colab.research.google.com/drive/1ru_4pFdCwJPwbEi9CnhNOArHSA3XkVAj?usp=sharing
'프로젝트 단위 공부 > [부스트코스] DataLit : 데이터 다루기' 카테고리의 다른 글
| Ch2-3. PySpark (0) | 2023.08.01 |
|---|---|
| Ch2-1. 하둡 (0) | 2023.07.31 |
| Ch1-12. 데이터 시각화 도구 (0) | 2023.07.24 |
| Ch1-11. 차원 축소 (0) | 2023.07.24 |
| Ch1-9. 데이터 시각화하기 (0) | 2023.07.21 |