
과제 개요
- 데이터 탐색과 정리
- 데이터 시각화와 스토리텔링
- 기계 학습 모델 구축
- 교차 검증과 개선 (특징 공학과 하이퍼파라미터 최적화)
- 엔드-투-엔드 아키텍처와 실제 기계 학습 연구 배포
최종 과제
- 구글 코랩, 주피터, 제플린, 또는 d3.js를 이용
- 깃허브 저장소에 저장
단계 1. 관심 있는 분야와 데이터셋 선택
나는 축구에 관심이 많기에 축구 데이터를 한 번 분석해보고자 한다. Kaggle의 "FIFA 23 Players Dataset" 데이터를 활용할 것이다. 약 18000명의 축구선수에 대한 데이터로 89개의 컬럼으로 이뤄져 있다.
Fifa 23 Players Dataset
Official Fifa 23 Player Stats
www.kaggle.com
단계 2-1. 데이터 탐색 및 데이터셋 정제
- 판다스의 profiling이나 describe를 이용하여 데이터셋 확인
데이터 불러오기
data = pd.read_csv("Fifa_23_Players_Data.csv")총 89 개의 컬럼, 18539 명의 선수 데이터
len(data), len(data.columns)
# (18539, 89)
data.columns
# Index(['Known As', 'Full Name', 'Overall', 'Potential', 'Value(in Euro)',
# 'Positions Played', 'Best Position', 'Nationality', 'Image Link', 'Age',
# 'Height(in cm)', 'Weight(in kg)', 'TotalStats', 'BaseStats',
# 'Club Name', 'Wage(in Euro)', 'Release Clause', 'Club Position',
# 'Contract Until', 'Club Jersey Number', 'Joined On', 'On Loan',
# 'Preferred Foot', 'Weak Foot Rating', 'Skill Moves',
# 'International Reputation', 'National Team Name',
# 'National Team Image Link', 'National Team Position',
# 'National Team Jersey Number', 'Attacking Work Rate',
# 'Defensive Work Rate', 'Pace Total', 'Shooting Total', 'Passing Total',
# 'Dribbling Total', 'Defending Total', 'Physicality Total', 'Crossing',
# 'Finishing', 'Heading Accuracy', 'Short Passing', 'Volleys',
# 'Dribbling', 'Curve', 'Freekick Accuracy', 'LongPassing', 'BallControl',
# 'Acceleration', 'Sprint Speed', 'Agility', 'Reactions', 'Balance',
# 'Shot Power', 'Jumping', 'Stamina', 'Strength', 'Long Shots',
# 'Aggression', 'Interceptions', 'Positioning', 'Vision', 'Penalties',
# 'Composure', 'Marking', 'Standing Tackle', 'Sliding Tackle',
# 'Goalkeeper Diving', 'Goalkeeper Handling', ' GoalkeeperKicking',
# 'Goalkeeper Positioning', 'Goalkeeper Reflexes', 'ST Rating',
# 'LW Rating', 'LF Rating', 'CF Rating', 'RF Rating', 'RW Rating',
# 'CAM Rating', 'LM Rating', 'CM Rating', 'RM Rating', 'LWB Rating',
# 'CDM Rating', 'RWB Rating', 'LB Rating', 'CB Rating', 'RB Rating',
# 'GK Rating'],
# dtype='object')모든 데이터에 null은 없으나 확인 결과 데이터가 없으면 '-'로 표시되어 있음
data.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 18539 entries, 0 to 18538
# Data columns (total 89 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 Known As 18539 non-null object
# 1 Full Name 18539 non-null object
# 2 Overall 18539 non-null int64
# 3 Potential 18539 non-null int64
# 4 Value(in Euro) 18539 non-null int64
# 5 Positions Played 18539 non-null object
# ...(중략)
# 81 RM Rating 18539 non-null int64
# 82 LWB Rating 18539 non-null int64
# 83 CDM Rating 18539 non-null int64
# 84 RWB Rating 18539 non-null int64
# 85 LB Rating 18539 non-null int64
# 86 CB Rating 18539 non-null int64
# 87 RB Rating 18539 non-null int64
# 88 GK Rating 18539 non-null int64
# dtypes: int64(71), object(18)
# memory usage: 12.6+ MB데이터 요약
data.describe()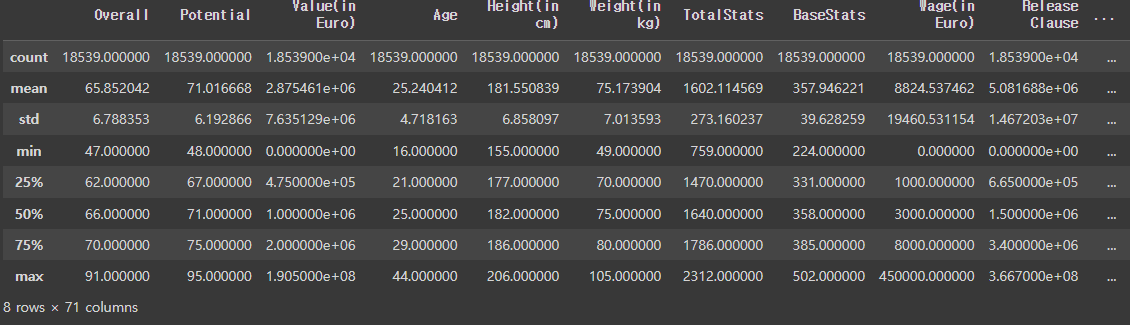
단계 2-2. 데이터셋 정제
- 누락된 값을 채워 넣을 수 있는 함수 추가
- 데이터 사이언티스트가 이해할 수 있도록 데이터를 설명하는 3개의 시각화 자료 생성
데이터 분석을 위한 데이터 컬럼 선택
col = ['Known As', 'Overall', 'Potential', 'Value(in Euro)', 'Best Position', 'Age', 'Height(in cm)',
'Weight(in kg)', 'TotalStats', 'BaseStats', 'Weak Foot Rating', 'Skill Moves',
'International Reputation', 'Shooting Total', 'Passing Total', 'Dribbling Total',
'Defending Total', 'Physicality Total', 'Crossing', 'Finishing', 'Heading Accuracy',
'Short Passing', 'Volleys', 'Dribbling', 'Curve', 'Freekick Accuracy', 'LongPassing',
'BallControl', 'Acceleration', 'Sprint Speed', 'Agility', 'Reactions', 'Balance',
'Shot Power', 'Jumping', 'Stamina', 'Strength', 'Long Shots', 'Aggression', 'Interceptions',
'Positioning', 'Vision', 'Penalties', 'Composure', 'Marking', 'Standing Tackle',
'Sliding Tackle', 'Goalkeeper Diving', 'Goalkeeper Handling', ' GoalkeeperKicking',
'Goalkeeper Positioning', 'Goalkeeper Reflexes']
data = data[col]누락된 값(null) 채우기
'Best Position'이 같은 선수들의 능력치의 중앙값으로 대체하여 누락된 값을 채운다. 아래 코드에는 'Marking'을 예시로 들었지만, 컬럼을 조정하면 모든 능력치 컬럼에 적용 가능하다.
# 해당 데이터에는 null이 존재하지 않지만, 만약 존재 했다면?
# 선수들의 능력치에 null이 있을 경우
pos = data['Best Position'].unique()
# array(['CAM', 'CF', 'ST', 'CM', 'RW', 'GK', 'CB', 'LW', 'CDM', 'LM', 'LB',
# 'RM', 'RB', 'LWB', 'RWB'], dtype=object)
data.groupby(['Best Position']).median()['Marking']
# Best Position
# CAM 44.0
# CB 65.0
# CDM 65.0
# CF 35.0
# CM 61.0
# GK 12.0
# LB 61.0
# LM 41.0
# LW 33.0
# LWB 60.0
# RB 62.0
# RM 40.0
# RW 35.0
# RWB 60.5
# ST 26.0
for p, m in data.groupby(['Best Position']).median()['Marking'].items():
data.loc[data['Best Position'] == p, 'Marking'] = data.loc[data['Best Position'] == p, 'Marking'].fillna(m)데이터 시각화
단계 3. 스토리텔링
- 데이터를 정제하게 된 목적과 문제를 해결하기 위해 어떤 모델을 만들 건지 설명하는 보고서 제작
- 보고서는 회사의 최고 경영자에게 보여줄 수 있을 정도의 수준
<능력치의 누락된 값(null)을 채우기 위해 Best Position이 같은 선수들의 능력치 중앙값으로 대체>
결측치를 채우기 위한 방법으로는 여러 가지가 있다. 먼저 해당 컬럼의 평균값, 중앙값, 최빈값 등 수치적 통계를 활용하는 방법과 해당 값의 앞뒤 행 값을 참고하여 대체하는 방법이 있다. 그러나 선수들의 포지션은 모두 다르며, 시계열 데이터가 아니기에 설명한 방법으로는 오차가 클 가능성이 매우 높다. 또한 describe를 살펴보면 Overall의 min과 max 간의 차이가 약 44로 크다고 생각했지만, 평균값(65.9)과 중앙값(66)의 차이가 크지 않아 어떤 통계값을 활용해도 상관없다고 판단하였지만 min과 max의 차이를 고려하고자 중앙값으로 결측치를 대체하였다.
<3개의 그래프>
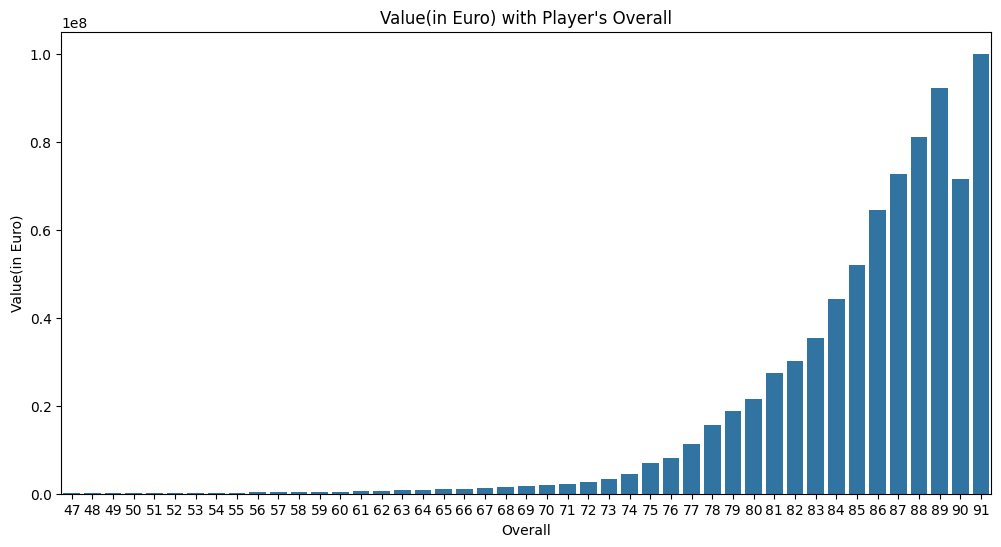
- 'Value(in Euro)'(세로)와 'Overall'(가로)를 활용한 시각화(단, 평균 Value)
=> 능력치에 따라 가치가 다른가?
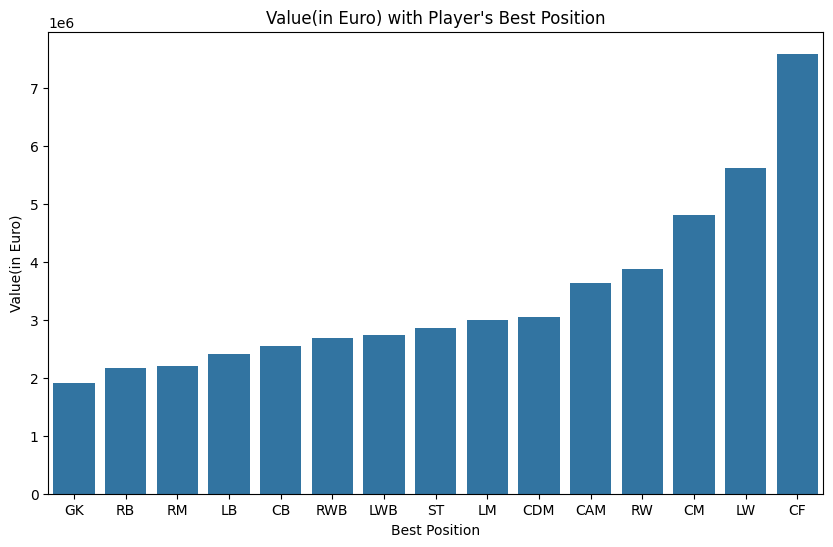
- 'Value(in Euro)'(세로)와 'Best Position'(가로)를 활용한 시각화(단, 평균 Value)
=> 포지션에 따라 가치가 다른가?
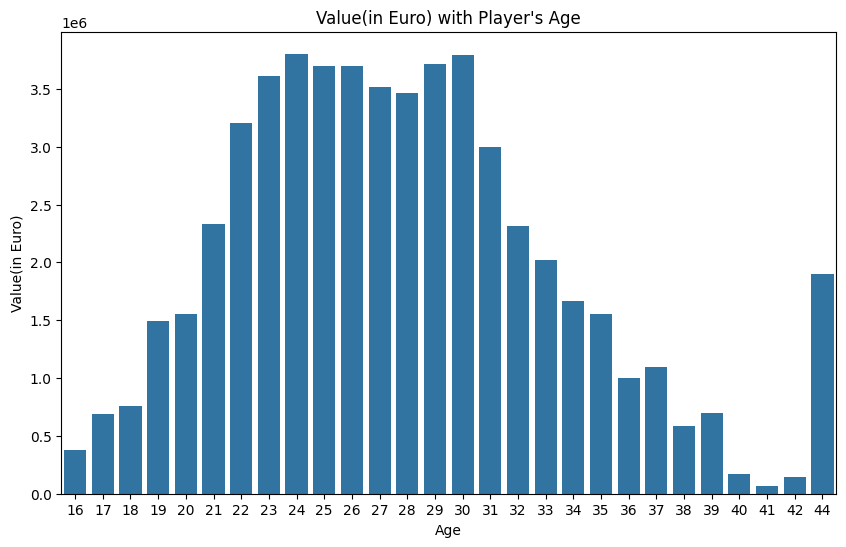
- 'Value(in Euro)'(세로)와 'Age'(가로)를 활용한 시각화(단, 평균 Value)
=> 나이에 따라 가치가 다른가?
그래프에서는 능력치, 포지션, 나이에 따라 가치가 어떻게 변하는지 살펴보았다.
Overall은 47 ~ 91까지 존재했으며, 90을 제외하고 능력치가 높을수록 가치가 높았다. 90은 87과 비슷한 수준의 가치로 일관성을 깨는 결과가 나왔다.
Best Position은 총 15개의 포지션 중 골키퍼(GK)가 가장 낮은 가치, CF가 가장 높은 가치를 가진다는 결과가 나왔다.
Age는 대체로 선수들의 기량이 높은 시기인 20대 초반에서 30대 초반까지 높은 가치를 보였다. 그러나 44세에 가치가 높은데, 이는 이탈리아의 Buffon(GK) 선수 1명으로 높은 인지도와 경력으로 높은 가치가 나타난 것으로 보인다.
단계 4. ML 모델 - Random Forest 적용
- 기계 학습 모델 만들기
- 왜 문제를 해결하기 위해 이 알고리즘을 선택했는지 기술
랜덤 포레스트
- 랜덤 포레스트는 의사결정나무를 배깅 방식으로 만든 알고리즘
- 모 데이터에서 n개의 샘플 데이터를 중복으로 허용해 무작위 추출 및 여러 개의 의사 결정나무 학습기를 통한 학습
- 배깅(Bagging) : 데이터를 무작위로 추출해 병렬적으로 학습한 결과를 다수결이나 평균으로 결정하는 것
ML을 위한 데이터 전처리
선수들의 Value(in Euro)를 예측할 것이므로 해당 컬럼을 y_train으로 설정 및 해당 컬럼을 제외한 컬럼을 x_train으로 설정하였다. 또한 Random Forest에서 문자열이 포함된 컬럼이 있으면 에러가 발생하므로 Best Position 컬럼은 LabelEncoder를 통해 인코딩 작업을 하였다.
x_train = data.drop(['Value(in Euro)', 'Known As'], axis=1)
y_train = data['Value(in Euro)'].reset_index(drop=True)from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
encoder.fit(x_train['Best Position'])
x_train['Best Position'] = encoder.transform(x_train['Best Position'])랜덤포레스트 및 교차검증을 활용한 회귀 예측 모델
랜덤포레스트와 StratifiedkFold 교차검증을 통해 예측값을 생성하였고, rmse를 통해 오차를 계산하였다. 그런데 오차가 생각보다 크게 나와 당황하였다. 아래의 그래프로 보면 얼추 잘 예측한 것 같지만, 단위가 커서 오차가 크게 나오는 듯하다.
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(random_state= 42, n_jobs = -1, n_estimators = 100)
model.fit(x_train, y_train)from sklearn.model_selection import cross_val_predict
from sklearn.model_selection import StratifiedKFold
y_predict = cross_val_predict(model, x_train, y_train, cv = StratifiedKFold(), n_jobs = -1, verbose = 2)from sklearn.metrics import mean_squared_error
import numpy as np
np.sqrt(mean_squared_error(y_train, y_predict))
# 1900903.7470149822결과
데이터를 모두 표시하면 너무 많아서 1/15 정도만 그래프에 나타내어 비교하였다.
plt.figure(figsize=(10, 7))
plt.title("Random Forest Prediction")
index = list(set([i//15 for i in range(len(y_train))]))
sns.lineplot(y_train[index], label='label')
sns.lineplot(y_predict[index], label='predict')
plt.legend()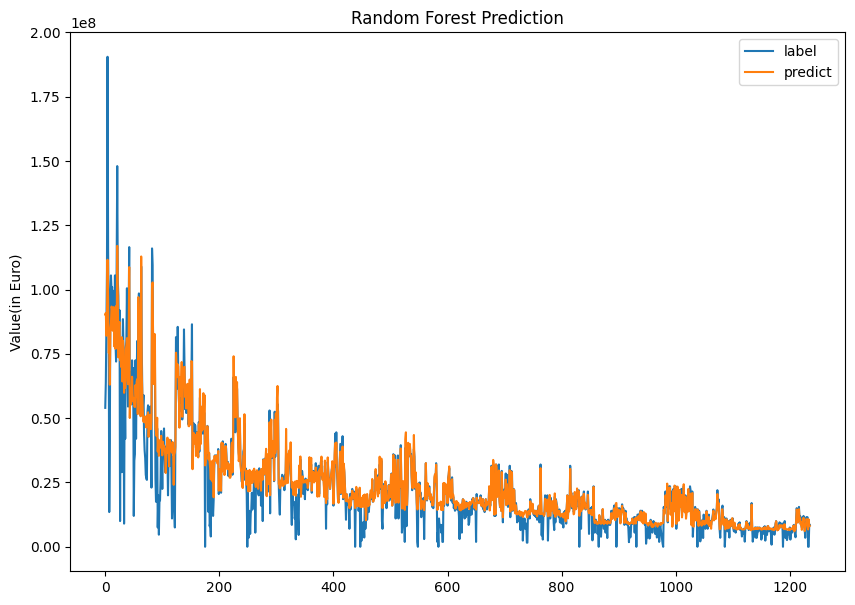
단계 5. 교차 검증 & 모델 개선
- 교차 검증 유형 기술
- 사용한 하이퍼 파라미터를 열거하고 코드에 주석으로 달기
교차 검증 - StratifiedkFold
단계 4의 코드를 그대로 가져온 것이다. k-Fold 교차 검증은 일정한 간격으로 잘라서 사용하여 비슷한 데이터가 한쪽에 몰려있을 경우 제대로 학습할 수 없다. 이 경우를 해결하기 위해 사용되는 것이 StratifiedkFold이며 target 속성값의 개수를 동일하게 가져감으로써 k-Fold처럼 데이터가 한 곳으로 몰리는 것을 방지한다.
from sklearn.model_selection import cross_val_predict
from sklearn.model_selection import StratifiedKFold
y_predict = cross_val_predict(model, x_train, y_train, cv = StratifiedKFold(), n_jobs = -1, verbose = 2)하이퍼 파라미터
단계 4의 코드를 그대로 가져온 것이다. 여기서 쓰인 하이퍼 파라미터는 random_state와 n_jobs, n_estimators이다. 여기서 n_estimators는 결정 트리의 개수를 의미한다. 많은 하이퍼 파라미터가 존재하지만, 학습 속도를 고려하여 간단하게만 적용하였다.
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(random_state= 42, n_jobs = -1, n_estimators = 100)
model.fit(x_train, y_train)참고 링크
DataLit : 데이터 다루기
https://www.boostcourse.org/ds103/joinLectures/84465
[3분 알고리즘] 랜덤 포레스트
https://blog-ko.superb-ai.com/3-minute-algorithm-random-forest/
[Python] 성능 측정 지표 :: MAE, MSE, RMSE, MAPE, MPE, MSLE
https://mizykk.tistory.com/102
교차 검증(cross validation)
https://erdnussretono.tistory.com/44
[ML/DL] python을 통한 교차검증 ( k - Fold, stratifiedkFold )
랜덤 포레스트(Random forest)
전체 코드 - Colab
https://colab.research.google.com/drive/1rxyUDV3IZYlniGfk9yOntRgoMakR3v-a#scrollTo=CwqPZ1yYOJnP
'프로젝트 단위 공부 > [부스트코스] DataLit : 데이터 다루기' 카테고리의 다른 글
| DataLit : 데이터 다루기 마무리 (0) | 2024.03.25 |
|---|---|
| Ch3-4. 데이터 스토리텔링 파트 2 (2) | 2024.03.18 |
| Ch3-3. 데이터 스토리텔링 파트 1 (0) | 2024.03.17 |
| Ch3-1. 데이터 사이언스 발표 가이드 (0) | 2024.03.16 |
| Ch2-과제. 파이스파크 (0) | 2024.03.15 |
과제 개요
- 데이터 탐색과 정리
- 데이터 시각화와 스토리텔링
- 기계 학습 모델 구축
- 교차 검증과 개선 (특징 공학과 하이퍼파라미터 최적화)
- 엔드-투-엔드 아키텍처와 실제 기계 학습 연구 배포
최종 과제
- 구글 코랩, 주피터, 제플린, 또는 d3.js를 이용
- 깃허브 저장소에 저장
단계 1. 관심 있는 분야와 데이터셋 선택
나는 축구에 관심이 많기에 축구 데이터를 한 번 분석해보고자 한다. Kaggle의 "FIFA 23 Players Dataset" 데이터를 활용할 것이다. 약 18000명의 축구선수에 대한 데이터로 89개의 컬럼으로 이뤄져 있다.
Fifa 23 Players Dataset
Official Fifa 23 Player Stats
www.kaggle.com
단계 2-1. 데이터 탐색 및 데이터셋 정제
- 판다스의 profiling이나 describe를 이용하여 데이터셋 확인
데이터 불러오기
data = pd.read_csv("Fifa_23_Players_Data.csv")총 89 개의 컬럼, 18539 명의 선수 데이터
len(data), len(data.columns)
# (18539, 89)
data.columns
# Index(['Known As', 'Full Name', 'Overall', 'Potential', 'Value(in Euro)',
# 'Positions Played', 'Best Position', 'Nationality', 'Image Link', 'Age',
# 'Height(in cm)', 'Weight(in kg)', 'TotalStats', 'BaseStats',
# 'Club Name', 'Wage(in Euro)', 'Release Clause', 'Club Position',
# 'Contract Until', 'Club Jersey Number', 'Joined On', 'On Loan',
# 'Preferred Foot', 'Weak Foot Rating', 'Skill Moves',
# 'International Reputation', 'National Team Name',
# 'National Team Image Link', 'National Team Position',
# 'National Team Jersey Number', 'Attacking Work Rate',
# 'Defensive Work Rate', 'Pace Total', 'Shooting Total', 'Passing Total',
# 'Dribbling Total', 'Defending Total', 'Physicality Total', 'Crossing',
# 'Finishing', 'Heading Accuracy', 'Short Passing', 'Volleys',
# 'Dribbling', 'Curve', 'Freekick Accuracy', 'LongPassing', 'BallControl',
# 'Acceleration', 'Sprint Speed', 'Agility', 'Reactions', 'Balance',
# 'Shot Power', 'Jumping', 'Stamina', 'Strength', 'Long Shots',
# 'Aggression', 'Interceptions', 'Positioning', 'Vision', 'Penalties',
# 'Composure', 'Marking', 'Standing Tackle', 'Sliding Tackle',
# 'Goalkeeper Diving', 'Goalkeeper Handling', ' GoalkeeperKicking',
# 'Goalkeeper Positioning', 'Goalkeeper Reflexes', 'ST Rating',
# 'LW Rating', 'LF Rating', 'CF Rating', 'RF Rating', 'RW Rating',
# 'CAM Rating', 'LM Rating', 'CM Rating', 'RM Rating', 'LWB Rating',
# 'CDM Rating', 'RWB Rating', 'LB Rating', 'CB Rating', 'RB Rating',
# 'GK Rating'],
# dtype='object')모든 데이터에 null은 없으나 확인 결과 데이터가 없으면 '-'로 표시되어 있음
data.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 18539 entries, 0 to 18538
# Data columns (total 89 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 Known As 18539 non-null object
# 1 Full Name 18539 non-null object
# 2 Overall 18539 non-null int64
# 3 Potential 18539 non-null int64
# 4 Value(in Euro) 18539 non-null int64
# 5 Positions Played 18539 non-null object
# ...(중략)
# 81 RM Rating 18539 non-null int64
# 82 LWB Rating 18539 non-null int64
# 83 CDM Rating 18539 non-null int64
# 84 RWB Rating 18539 non-null int64
# 85 LB Rating 18539 non-null int64
# 86 CB Rating 18539 non-null int64
# 87 RB Rating 18539 non-null int64
# 88 GK Rating 18539 non-null int64
# dtypes: int64(71), object(18)
# memory usage: 12.6+ MB데이터 요약
data.describe()단계 2-2. 데이터셋 정제
- 누락된 값을 채워 넣을 수 있는 함수 추가
- 데이터 사이언티스트가 이해할 수 있도록 데이터를 설명하는 3개의 시각화 자료 생성
데이터 분석을 위한 데이터 컬럼 선택
col = ['Known As', 'Overall', 'Potential', 'Value(in Euro)', 'Best Position', 'Age', 'Height(in cm)',
'Weight(in kg)', 'TotalStats', 'BaseStats', 'Weak Foot Rating', 'Skill Moves',
'International Reputation', 'Shooting Total', 'Passing Total', 'Dribbling Total',
'Defending Total', 'Physicality Total', 'Crossing', 'Finishing', 'Heading Accuracy',
'Short Passing', 'Volleys', 'Dribbling', 'Curve', 'Freekick Accuracy', 'LongPassing',
'BallControl', 'Acceleration', 'Sprint Speed', 'Agility', 'Reactions', 'Balance',
'Shot Power', 'Jumping', 'Stamina', 'Strength', 'Long Shots', 'Aggression', 'Interceptions',
'Positioning', 'Vision', 'Penalties', 'Composure', 'Marking', 'Standing Tackle',
'Sliding Tackle', 'Goalkeeper Diving', 'Goalkeeper Handling', ' GoalkeeperKicking',
'Goalkeeper Positioning', 'Goalkeeper Reflexes']
data = data[col]누락된 값(null) 채우기
'Best Position'이 같은 선수들의 능력치의 중앙값으로 대체하여 누락된 값을 채운다. 아래 코드에는 'Marking'을 예시로 들었지만, 컬럼을 조정하면 모든 능력치 컬럼에 적용 가능하다.
# 해당 데이터에는 null이 존재하지 않지만, 만약 존재 했다면?
# 선수들의 능력치에 null이 있을 경우
pos = data['Best Position'].unique()
# array(['CAM', 'CF', 'ST', 'CM', 'RW', 'GK', 'CB', 'LW', 'CDM', 'LM', 'LB',
# 'RM', 'RB', 'LWB', 'RWB'], dtype=object)
data.groupby(['Best Position']).median()['Marking']
# Best Position
# CAM 44.0
# CB 65.0
# CDM 65.0
# CF 35.0
# CM 61.0
# GK 12.0
# LB 61.0
# LM 41.0
# LW 33.0
# LWB 60.0
# RB 62.0
# RM 40.0
# RW 35.0
# RWB 60.5
# ST 26.0
for p, m in data.groupby(['Best Position']).median()['Marking'].items():
data.loc[data['Best Position'] == p, 'Marking'] = data.loc[data['Best Position'] == p, 'Marking'].fillna(m)데이터 시각화
단계 3. 스토리텔링
- 데이터를 정제하게 된 목적과 문제를 해결하기 위해 어떤 모델을 만들 건지 설명하는 보고서 제작
- 보고서는 회사의 최고 경영자에게 보여줄 수 있을 정도의 수준
<능력치의 누락된 값(null)을 채우기 위해 Best Position이 같은 선수들의 능력치 중앙값으로 대체>
결측치를 채우기 위한 방법으로는 여러 가지가 있다. 먼저 해당 컬럼의 평균값, 중앙값, 최빈값 등 수치적 통계를 활용하는 방법과 해당 값의 앞뒤 행 값을 참고하여 대체하는 방법이 있다. 그러나 선수들의 포지션은 모두 다르며, 시계열 데이터가 아니기에 설명한 방법으로는 오차가 클 가능성이 매우 높다. 또한 describe를 살펴보면 Overall의 min과 max 간의 차이가 약 44로 크다고 생각했지만, 평균값(65.9)과 중앙값(66)의 차이가 크지 않아 어떤 통계값을 활용해도 상관없다고 판단하였지만 min과 max의 차이를 고려하고자 중앙값으로 결측치를 대체하였다.
<3개의 그래프>
- 'Value(in Euro)'(세로)와 'Overall'(가로)를 활용한 시각화(단, 평균 Value)
=> 능력치에 따라 가치가 다른가?
- 'Value(in Euro)'(세로)와 'Best Position'(가로)를 활용한 시각화(단, 평균 Value)
=> 포지션에 따라 가치가 다른가?
- 'Value(in Euro)'(세로)와 'Age'(가로)를 활용한 시각화(단, 평균 Value)
=> 나이에 따라 가치가 다른가?
그래프에서는 능력치, 포지션, 나이에 따라 가치가 어떻게 변하는지 살펴보았다.
Overall은 47 ~ 91까지 존재했으며, 90을 제외하고 능력치가 높을수록 가치가 높았다. 90은 87과 비슷한 수준의 가치로 일관성을 깨는 결과가 나왔다.
Best Position은 총 15개의 포지션 중 골키퍼(GK)가 가장 낮은 가치, CF가 가장 높은 가치를 가진다는 결과가 나왔다.
Age는 대체로 선수들의 기량이 높은 시기인 20대 초반에서 30대 초반까지 높은 가치를 보였다. 그러나 44세에 가치가 높은데, 이는 이탈리아의 Buffon(GK) 선수 1명으로 높은 인지도와 경력으로 높은 가치가 나타난 것으로 보인다.
단계 4. ML 모델 - Random Forest 적용
- 기계 학습 모델 만들기
- 왜 문제를 해결하기 위해 이 알고리즘을 선택했는지 기술
랜덤 포레스트
- 랜덤 포레스트는 의사결정나무를 배깅 방식으로 만든 알고리즘
- 모 데이터에서 n개의 샘플 데이터를 중복으로 허용해 무작위 추출 및 여러 개의 의사 결정나무 학습기를 통한 학습
- 배깅(Bagging) : 데이터를 무작위로 추출해 병렬적으로 학습한 결과를 다수결이나 평균으로 결정하는 것
ML을 위한 데이터 전처리
선수들의 Value(in Euro)를 예측할 것이므로 해당 컬럼을 y_train으로 설정 및 해당 컬럼을 제외한 컬럼을 x_train으로 설정하였다. 또한 Random Forest에서 문자열이 포함된 컬럼이 있으면 에러가 발생하므로 Best Position 컬럼은 LabelEncoder를 통해 인코딩 작업을 하였다.
x_train = data.drop(['Value(in Euro)', 'Known As'], axis=1)
y_train = data['Value(in Euro)'].reset_index(drop=True)from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
encoder.fit(x_train['Best Position'])
x_train['Best Position'] = encoder.transform(x_train['Best Position'])랜덤포레스트 및 교차검증을 활용한 회귀 예측 모델
랜덤포레스트와 StratifiedkFold 교차검증을 통해 예측값을 생성하였고, rmse를 통해 오차를 계산하였다. 그런데 오차가 생각보다 크게 나와 당황하였다. 아래의 그래프로 보면 얼추 잘 예측한 것 같지만, 단위가 커서 오차가 크게 나오는 듯하다.
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(random_state= 42, n_jobs = -1, n_estimators = 100)
model.fit(x_train, y_train)from sklearn.model_selection import cross_val_predict
from sklearn.model_selection import StratifiedKFold
y_predict = cross_val_predict(model, x_train, y_train, cv = StratifiedKFold(), n_jobs = -1, verbose = 2)from sklearn.metrics import mean_squared_error
import numpy as np
np.sqrt(mean_squared_error(y_train, y_predict))
# 1900903.7470149822결과
데이터를 모두 표시하면 너무 많아서 1/15 정도만 그래프에 나타내어 비교하였다.
plt.figure(figsize=(10, 7))
plt.title("Random Forest Prediction")
index = list(set([i//15 for i in range(len(y_train))]))
sns.lineplot(y_train[index], label='label')
sns.lineplot(y_predict[index], label='predict')
plt.legend()단계 5. 교차 검증 & 모델 개선
- 교차 검증 유형 기술
- 사용한 하이퍼 파라미터를 열거하고 코드에 주석으로 달기
교차 검증 - StratifiedkFold
단계 4의 코드를 그대로 가져온 것이다. k-Fold 교차 검증은 일정한 간격으로 잘라서 사용하여 비슷한 데이터가 한쪽에 몰려있을 경우 제대로 학습할 수 없다. 이 경우를 해결하기 위해 사용되는 것이 StratifiedkFold이며 target 속성값의 개수를 동일하게 가져감으로써 k-Fold처럼 데이터가 한 곳으로 몰리는 것을 방지한다.
from sklearn.model_selection import cross_val_predict
from sklearn.model_selection import StratifiedKFold
y_predict = cross_val_predict(model, x_train, y_train, cv = StratifiedKFold(), n_jobs = -1, verbose = 2)하이퍼 파라미터
단계 4의 코드를 그대로 가져온 것이다. 여기서 쓰인 하이퍼 파라미터는 random_state와 n_jobs, n_estimators이다. 여기서 n_estimators는 결정 트리의 개수를 의미한다. 많은 하이퍼 파라미터가 존재하지만, 학습 속도를 고려하여 간단하게만 적용하였다.
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(random_state= 42, n_jobs = -1, n_estimators = 100)
model.fit(x_train, y_train)참고 링크
DataLit : 데이터 다루기
https://www.boostcourse.org/ds103/joinLectures/84465
[3분 알고리즘] 랜덤 포레스트
https://blog-ko.superb-ai.com/3-minute-algorithm-random-forest/
[Python] 성능 측정 지표 :: MAE, MSE, RMSE, MAPE, MPE, MSLE
https://mizykk.tistory.com/102
교차 검증(cross validation)
https://erdnussretono.tistory.com/44
[ML/DL] python을 통한 교차검증 ( k - Fold, stratifiedkFold )
랜덤 포레스트(Random forest)
전체 코드 - Colab
https://colab.research.google.com/drive/1rxyUDV3IZYlniGfk9yOntRgoMakR3v-a#scrollTo=CwqPZ1yYOJnP
'프로젝트 단위 공부 > [부스트코스] DataLit : 데이터 다루기' 카테고리의 다른 글
| DataLit : 데이터 다루기 마무리 (0) | 2024.03.25 |
|---|---|
| Ch3-4. 데이터 스토리텔링 파트 2 (2) | 2024.03.18 |
| Ch3-3. 데이터 스토리텔링 파트 1 (0) | 2024.03.17 |
| Ch3-1. 데이터 사이언스 발표 가이드 (0) | 2024.03.16 |
| Ch2-과제. 파이스파크 (0) | 2024.03.15 |